Redshiftは何回か構築したことがありましたが、記事として残したことはなかったので今更ですが残しておきます。
公式のチュートリアルを参考に実施していきます。
docs.aws.amazon.com
尚、公式に書いてある通り、以下の料金が発生するので気を付けてください。
作成するサンプルクラスターは、ライブ環境で実行されます。本チュートリアルで設計されるサンプルクラスターの使用については、サンプルクラスターを削除するまでのオンデマンドレートが 1 時間あたり 0.25 USD になります。
実施作業
準備
AWSアカウント及びVPCは事前に作成済みです。
作業ユーザは管理者相当の権限を持っています。
Redshiftの設定時に必要になるサブネットグループとセキュリティグループの作成は以下の手順で実施します。
サブネットグループ作成
Redshiftコンソールを開いて、左の設定からサブネットグループを選択します。

クラスターサブネットグループの作成を選択します。

サブネットグループを作成するVPCを選択して、VPC配下のサブネットをグループに割り当てます。
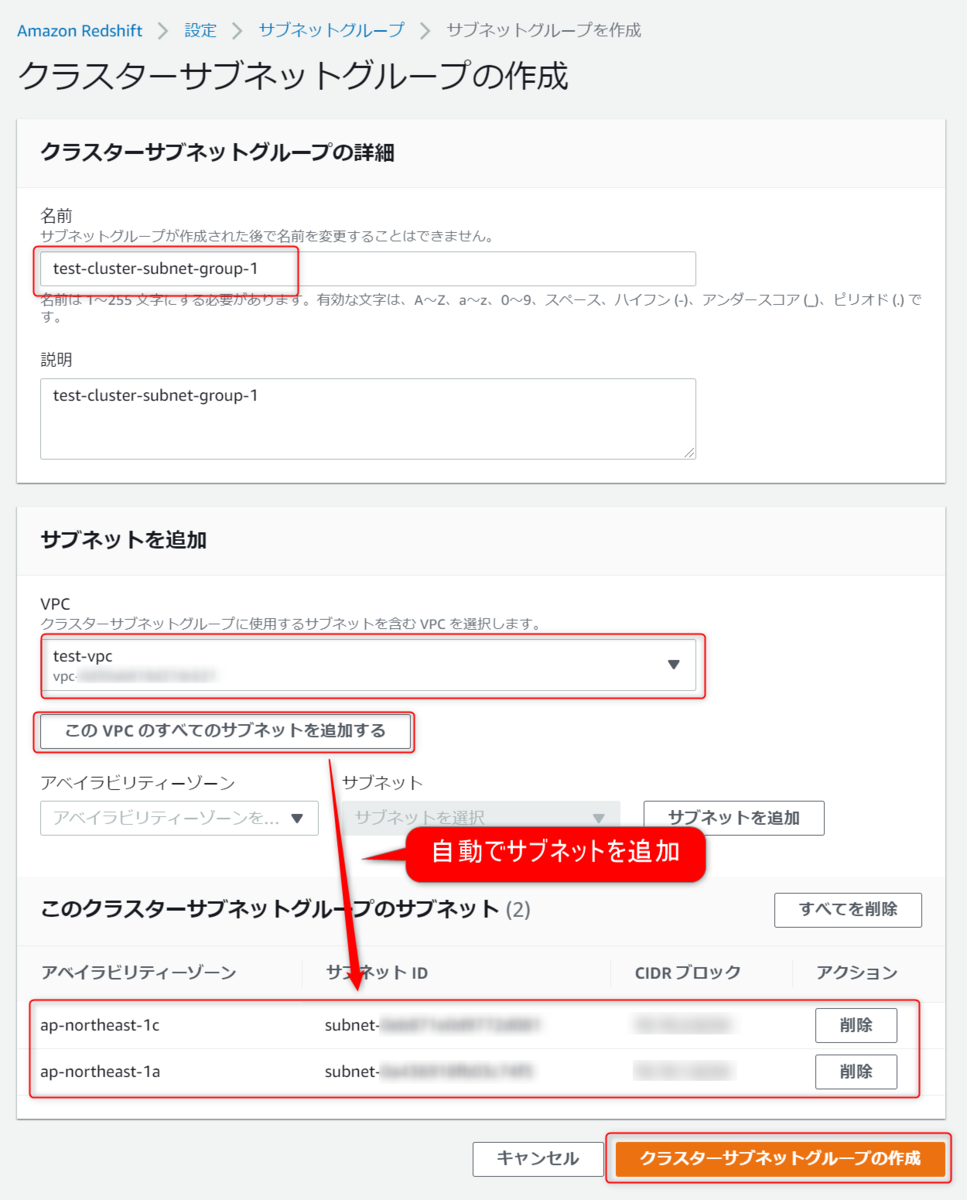
作成できました。
セキュリティグループ作成
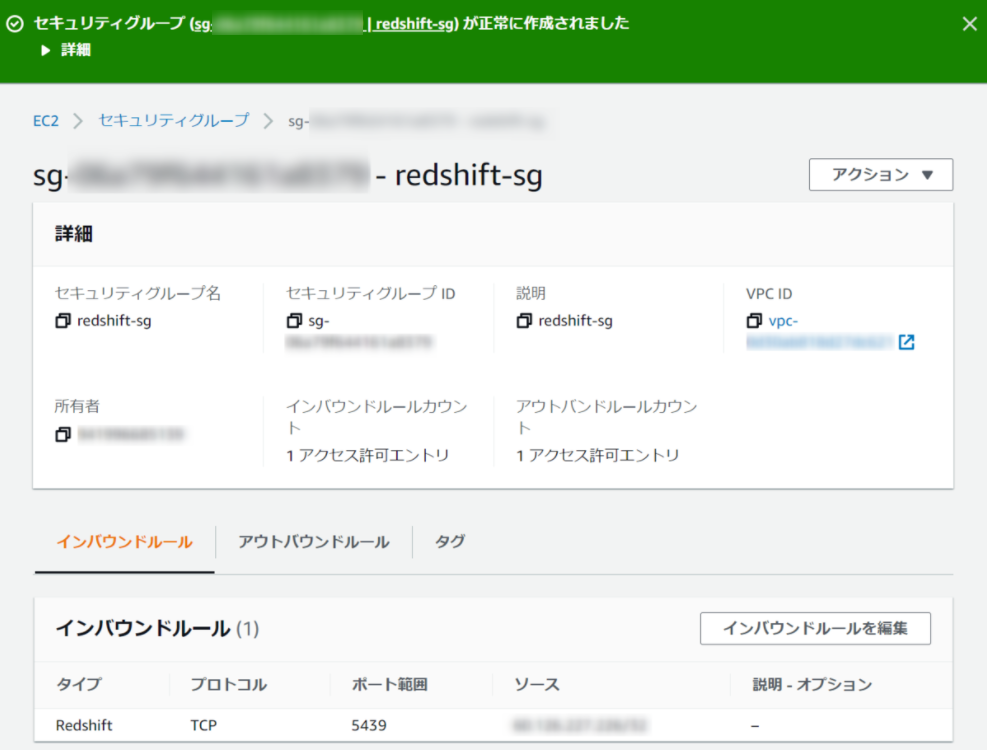
Redshiftクラスターに設定するセキュリティグループを作成します。
EC2コンソールを開いてセキュリティグループの作成を押下します。
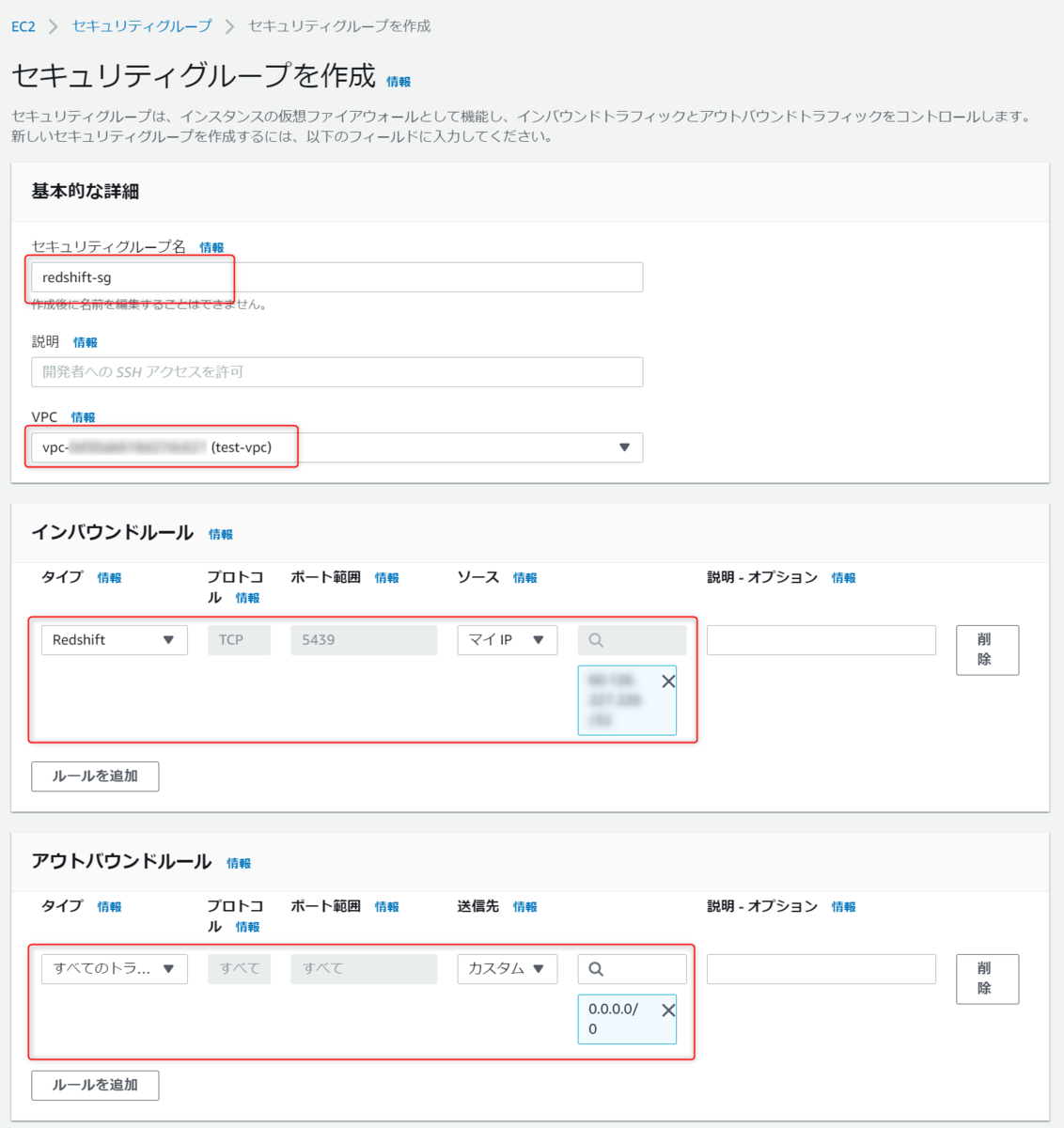
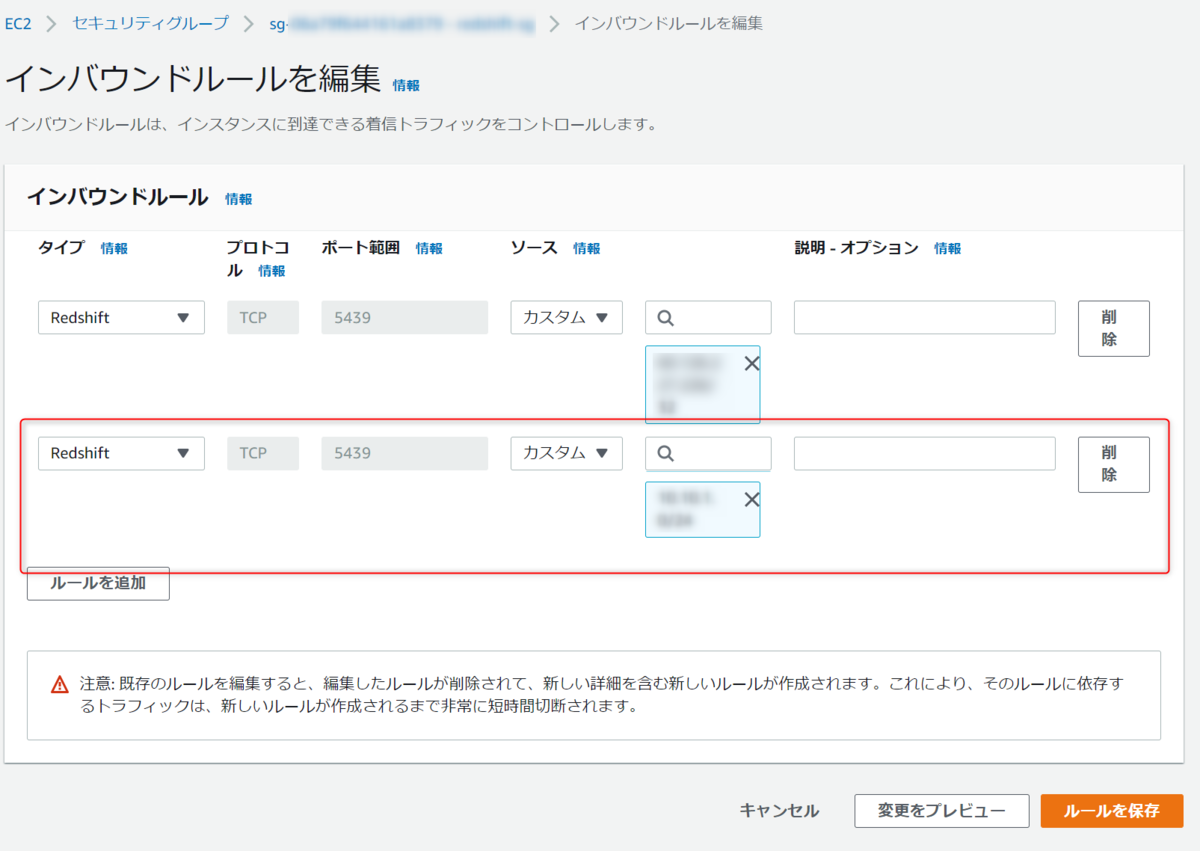
セキュリティグループ名を入力し、インバウンドルールとアウトバウントルールを設定します。
インバウンドルールはRedshiftのポートへの許可とアクセスする自分のIPを設定します。
アウトバウントルールはデフォルトにしておきます。
タグは設定せずにセキュリティグループを作成を押下します。
セキュリティグループが作成されました。
ステップ 1: 前提条件の設定
前提条件は以下の2つです。
1つ目は実施済みのためスキップするとして、2つ目はRedshiftへのアクセスするためのポートがネットワークとして許可されているかどうかを確認します。
RedshiftのポートはSQLクライアントツールからアクセスするときに必要になるので、もしプライベートなネットワーク上のコンピュータからRedshiftにアクセスする場合はFWなどが許可されているか見ておく必要があります。
今回は不要なのでスキップします。
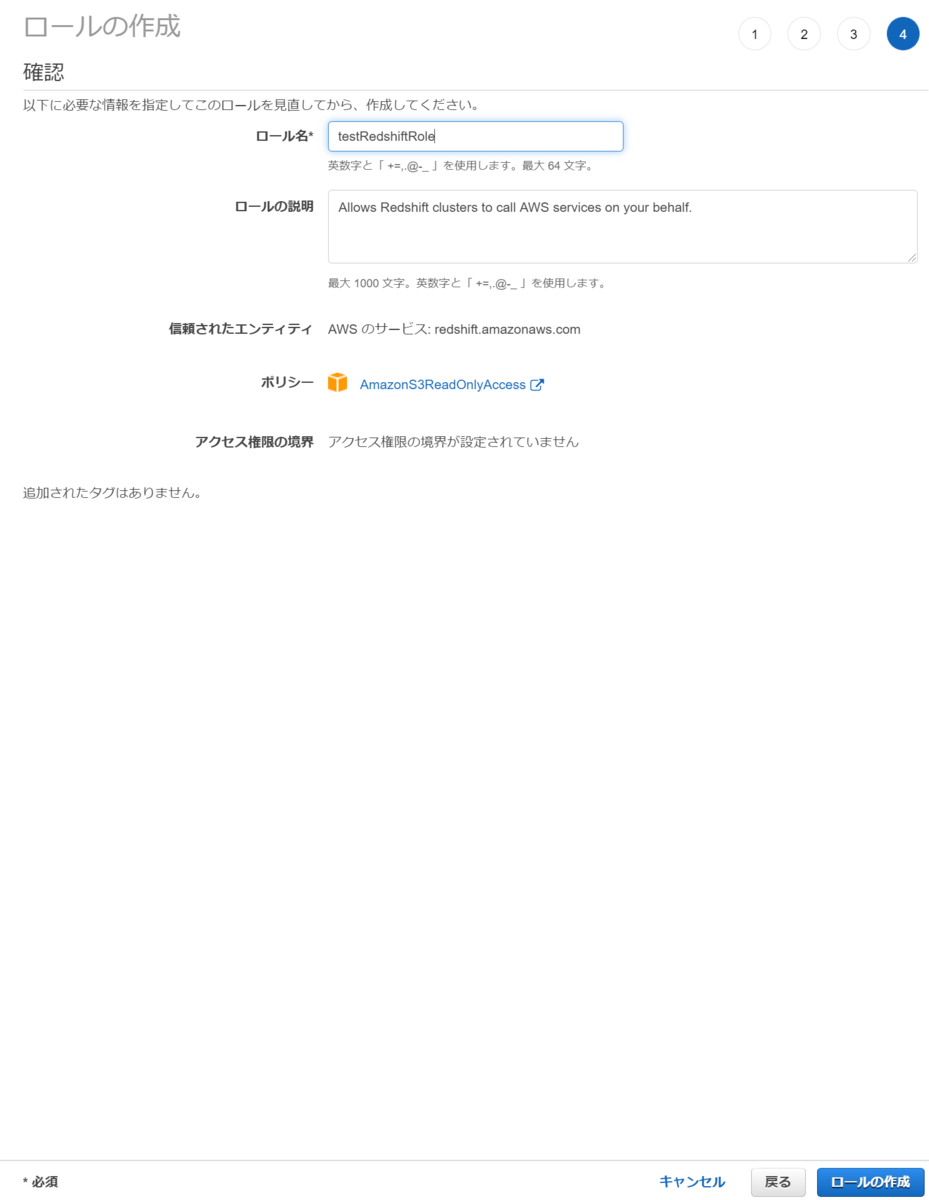
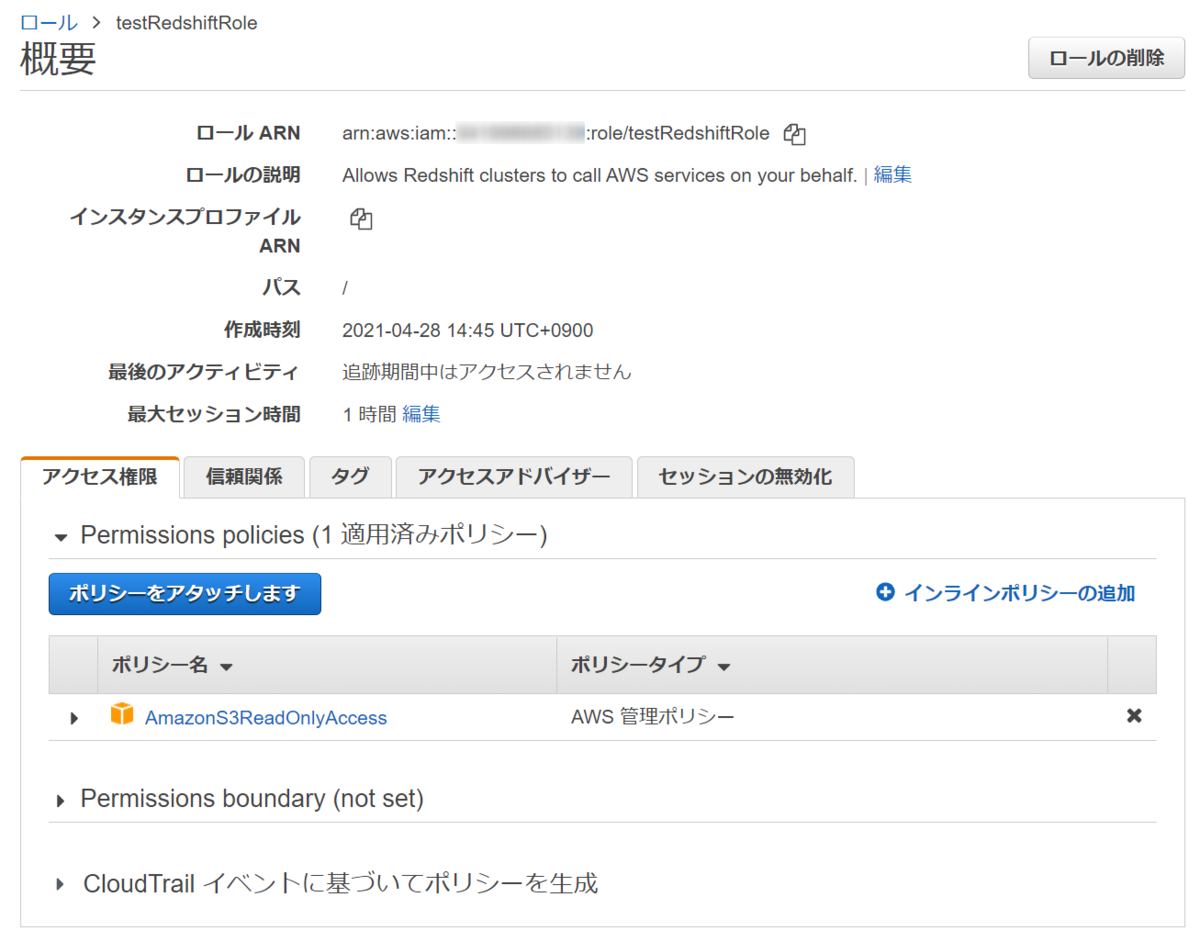
ステップ 2: IAM ロールを作成する
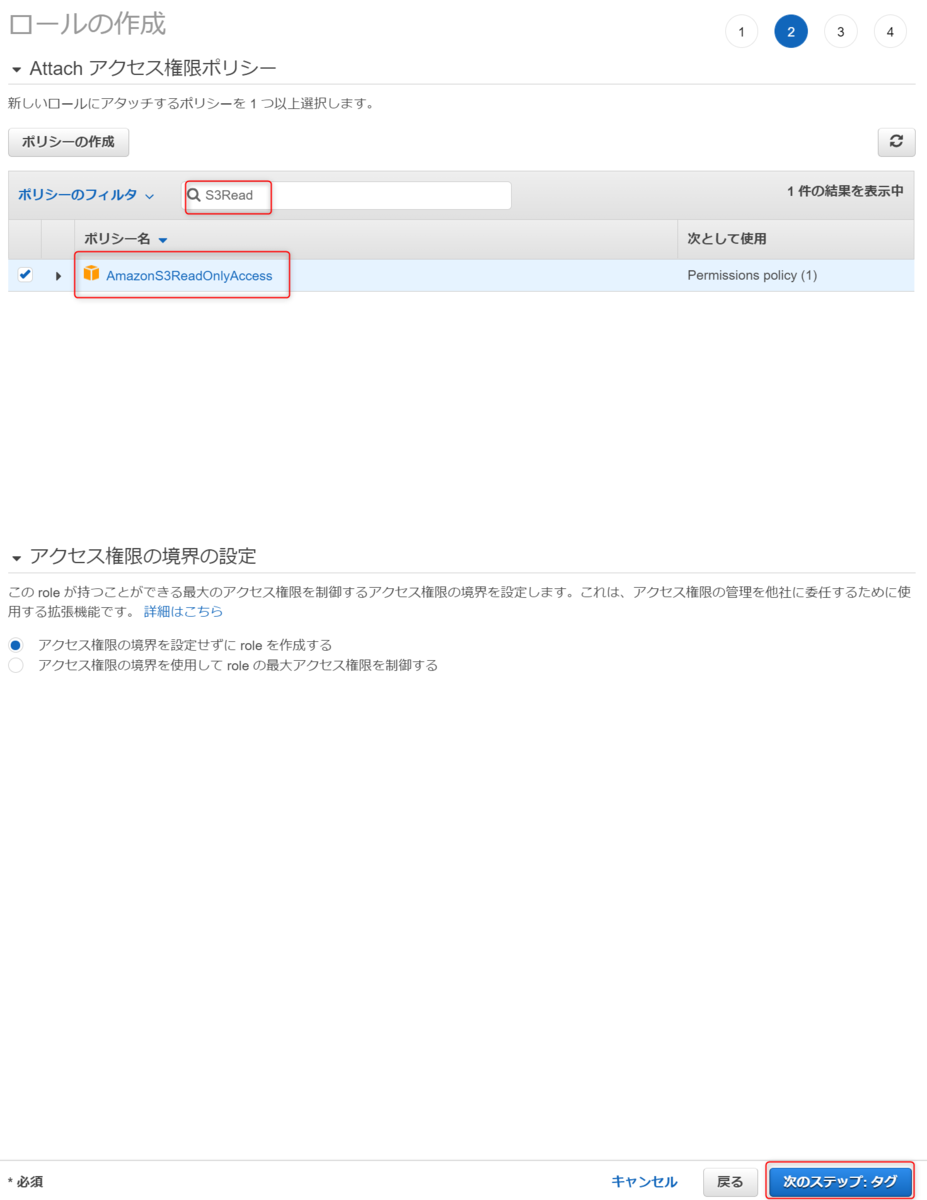
次はRedshiftに設定するIAMロールを設定します。
Redshiftの中にあるデータであれば、RedshiftのDBユーザ/パスワードが作成されていれば問題ないですが、S3上のCSVファイルをロードする、といったRedshift以外のAWSサービスと連携するときはRedshiftにアタッチされたIAMロールの権限が使用されます。



ステップ 3: サンプルAmazon Redshift クラスターの作成
IAMロールができたら次はRedshiftクラスターを作成していきます。
クラスター情報設定
Redshiftコンソールにアクセスし、クラスターを作成を押下します。

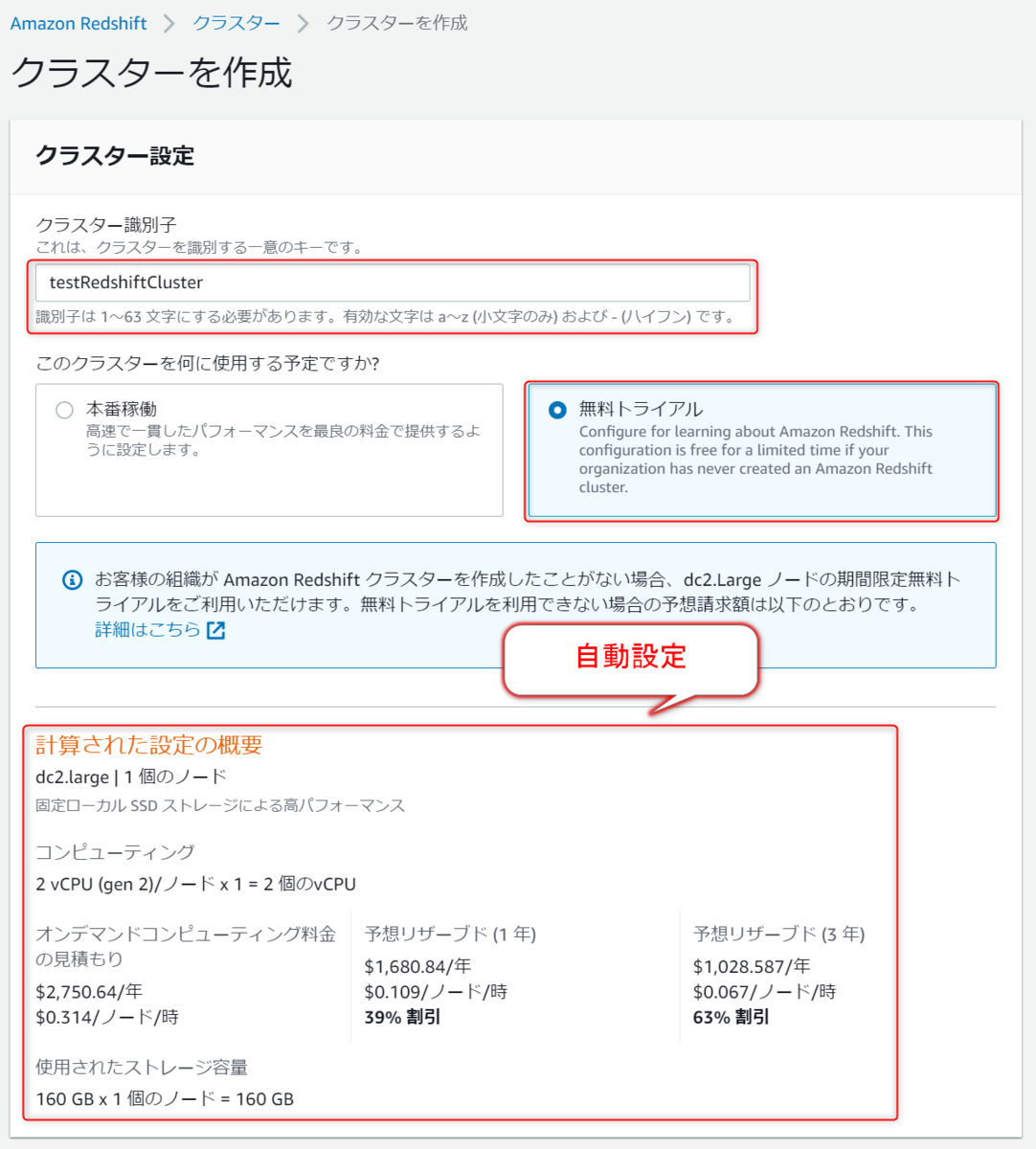
クラスター識別子(クラスターの名前)を入力し、無料トライアルを選択します。
すると自動で使用するノード・ストレージ・料金が決定します。
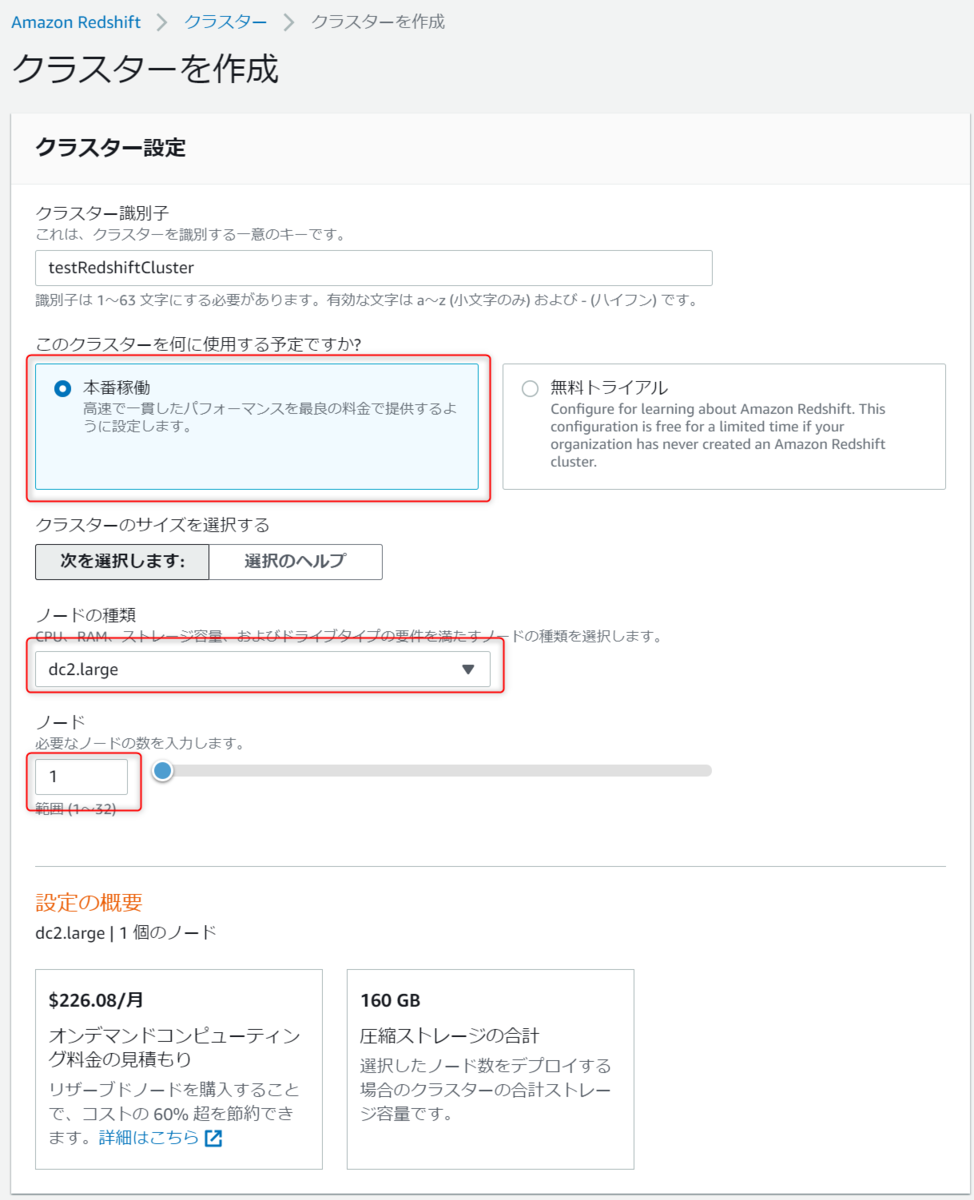
尚、本番稼働を選択するともう少し細かい設定が可能です。
ノードタイプdc2.large以外を使用したい場合はそちらを選択ください。
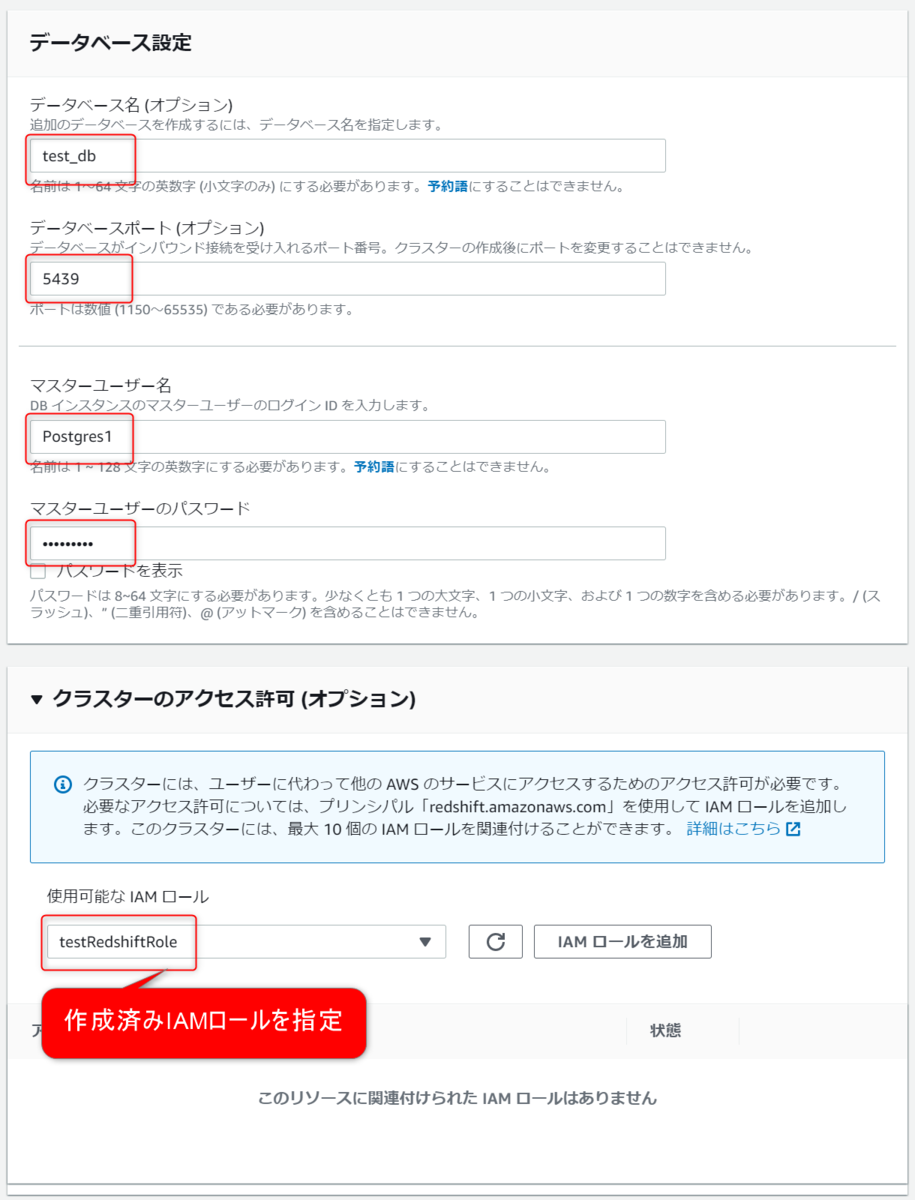
DB情報・IAM設定
次にRedshiftのDBとマスターユーザの設定をします。
またクラスターにアタッチするIAMロールもここで設定します。
オプション設定
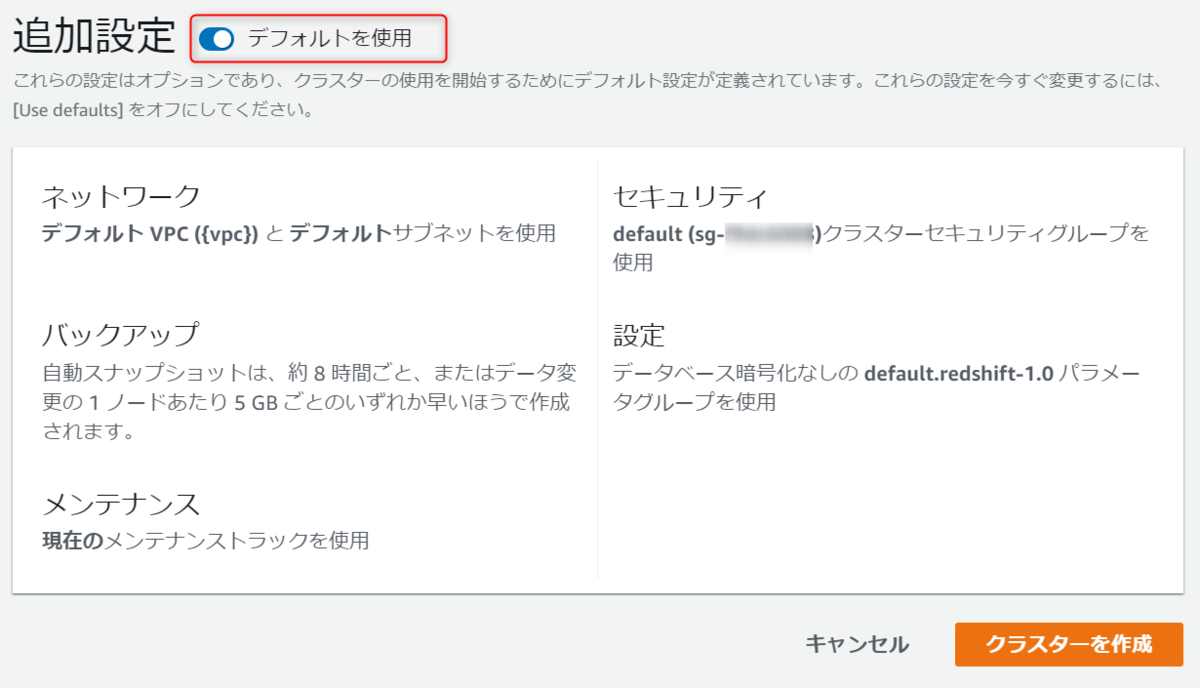
最後に追加のオプションを設定します。
何もしないとデフォルトのもので構築されますが、今回は敢えて手動で設定していきます。
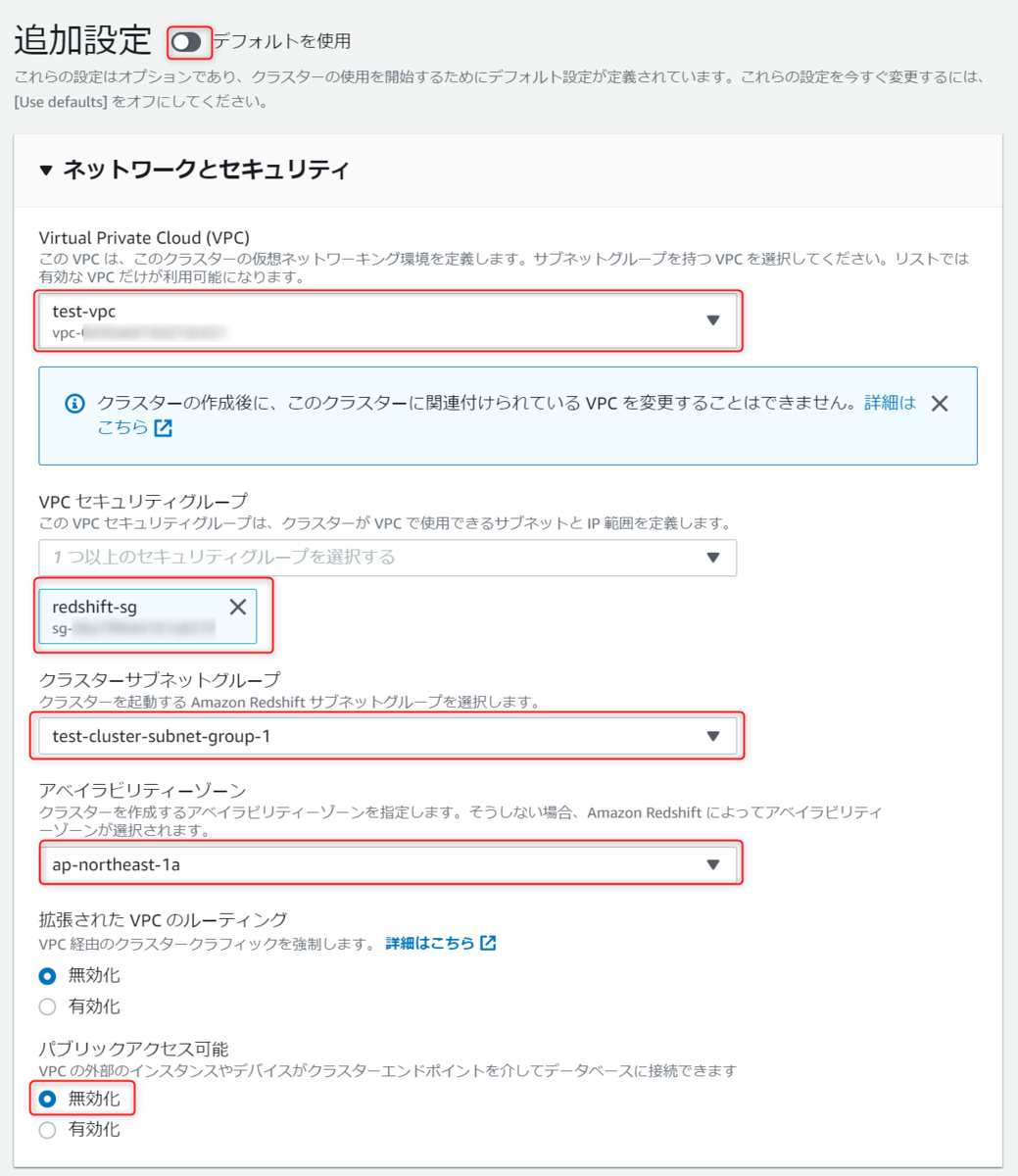
ネットワークとセキュリティは以下のように設定します。
それ以外はバックアップのスナップショット保持期間以外デフォルトで設定し、クラスターを作成を押下します。

以下の2つのエラーが出ました。

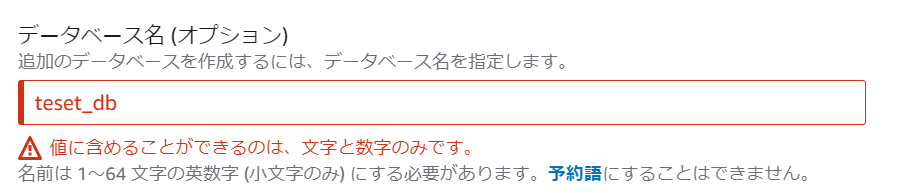
以下のように修正しました。


再度クラスターを作成を押下したところ、次は以下のエラーが発生しました。
原文
MasterUsername parameter must be lowercase, begin with a letter, contain only alphanumeric characters, underscore ('_'), plus sign ('+'), dot ('.'), at ('@'), or hyphen ('-'), and be less than 128 characters.
日本語訳
MasterUsernameパラメータは、小文字で、文字で始まり、英数字、アンダースコア('_')、プラス記号('+')、ドット('・')、アット('@')、またはハイフン('-')のみを含み、128文字以下である必要があります。
どうやら大文字が使えないみたいなので、小文字に修正します。

作成中になったので、クラスターが作成されるまでしばし待ちます。

ステップ 4: クラスターへのアクセスの許可
クエリエディタを使用せずにクラスターへのアクセスを確認します。
やりかたは色々ありますが、今回は同VPC上にあるEC2(Linux)からのアクセスを確認します。
まずはEC2を作成して、ローカルPCからSSHでログインします(手順全スキップ)
以下のコマンドを実行してpsqlコマンドを実行可能な状態にします。
sudo yum install postgresql -y
インストールができているとpsqlのヘルプコマンドが実行できるはずです。
Redshiftクラスターへの接続のためのコマンドは以下のドキュメントに書いてあるので、参考にしつつコマンドを作成します。
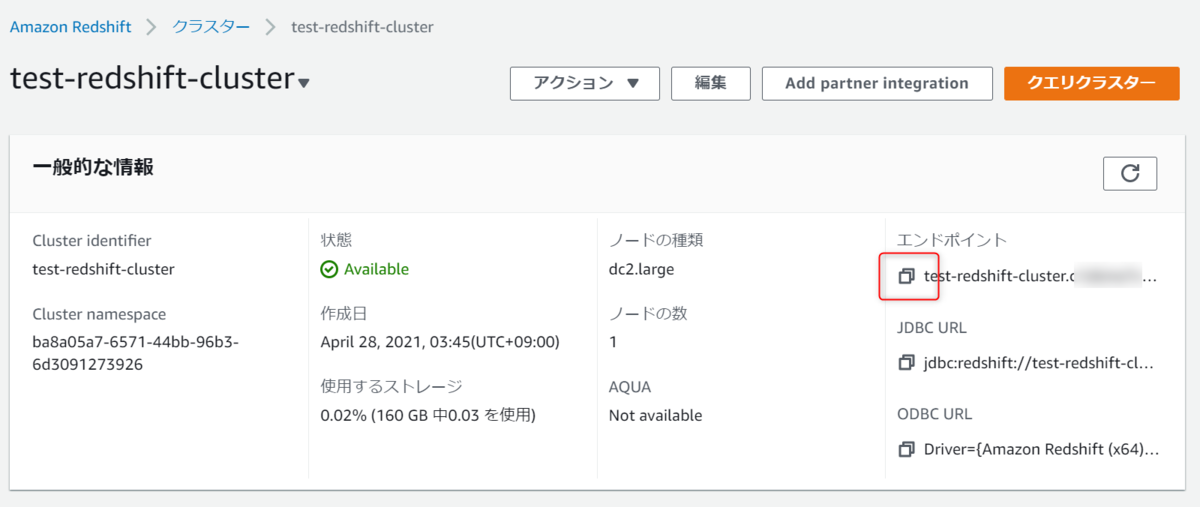
必要な情報はRedshiftクラスターの詳細設定を確認すると書いてあります。
docs.aws.amazon.com
以下をクリックすると必要な情報がコピーできると思います。
ポートやDB名なども一緒にコピーされるので、コマンドに転記するときはご注意ください。
実際にEC2からコマンドを実行すると以下のようにRedshiftクラスターに接続ができました。
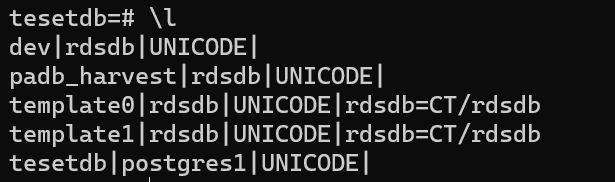
$ psql -h test-redshift-cluster.XXXXXXXXXX.ap-northeast-1.redshift.amazonaws.com -U postgres1 -d tesetdb -p 5439

"\l"を実行するとDB一覧が確認できます。
ステップ 5: クエリエディタへのアクセスを許可し、クエリを実行する
先ほど実施した内容をクエリエディタから実行してみます。
まずはRedshiftコンソールからクエリエディタを開きます。
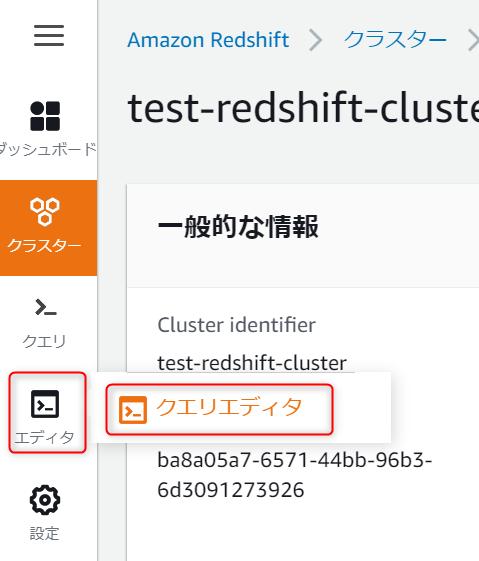
もしクエリエディタが開けなかった場合は以下のリンクを参考にIAMユーザの権限を確認してみてください。
docs.aws.amazon.com
クエリエディタが開くのでデータベースに接続を押下します。
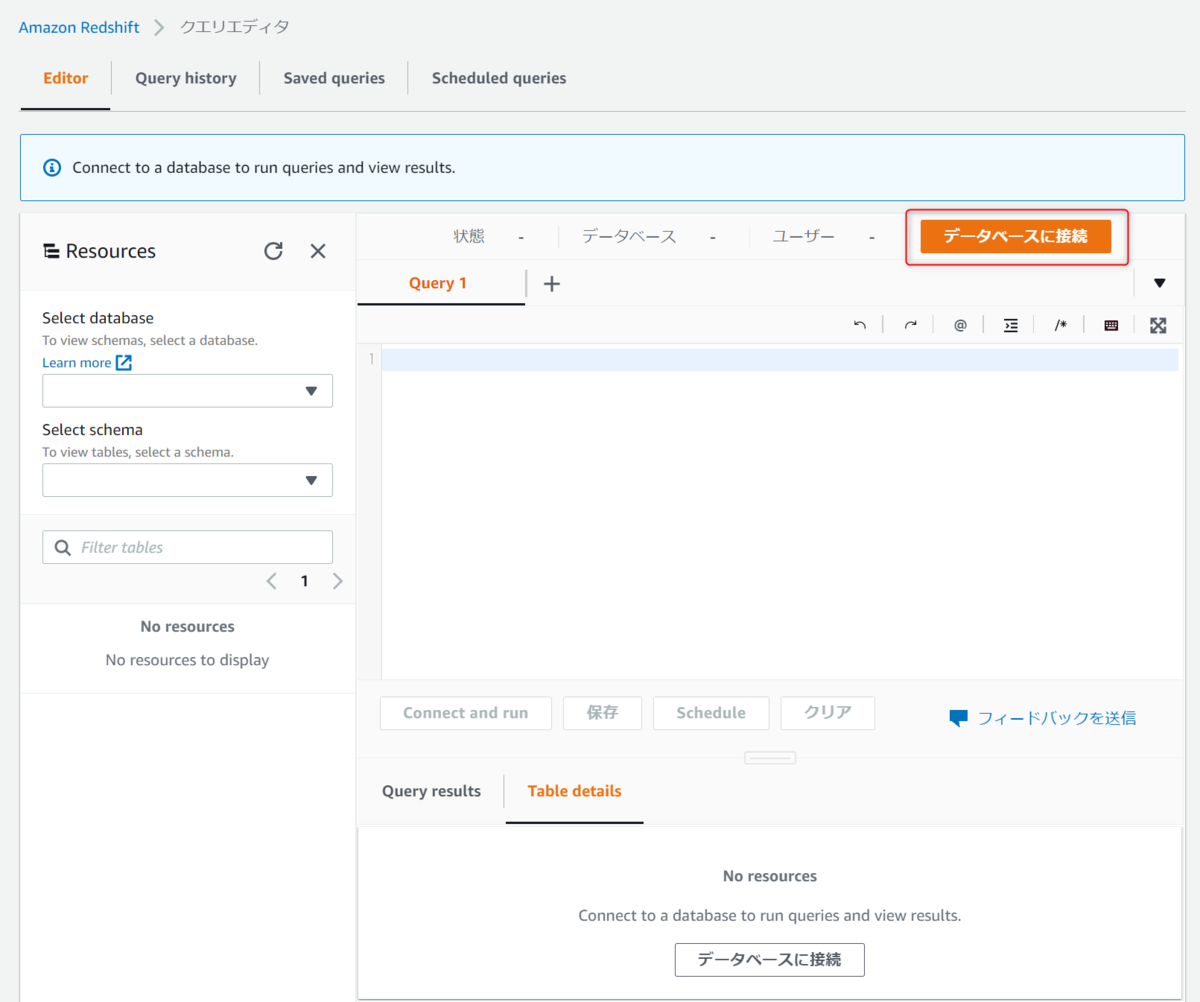
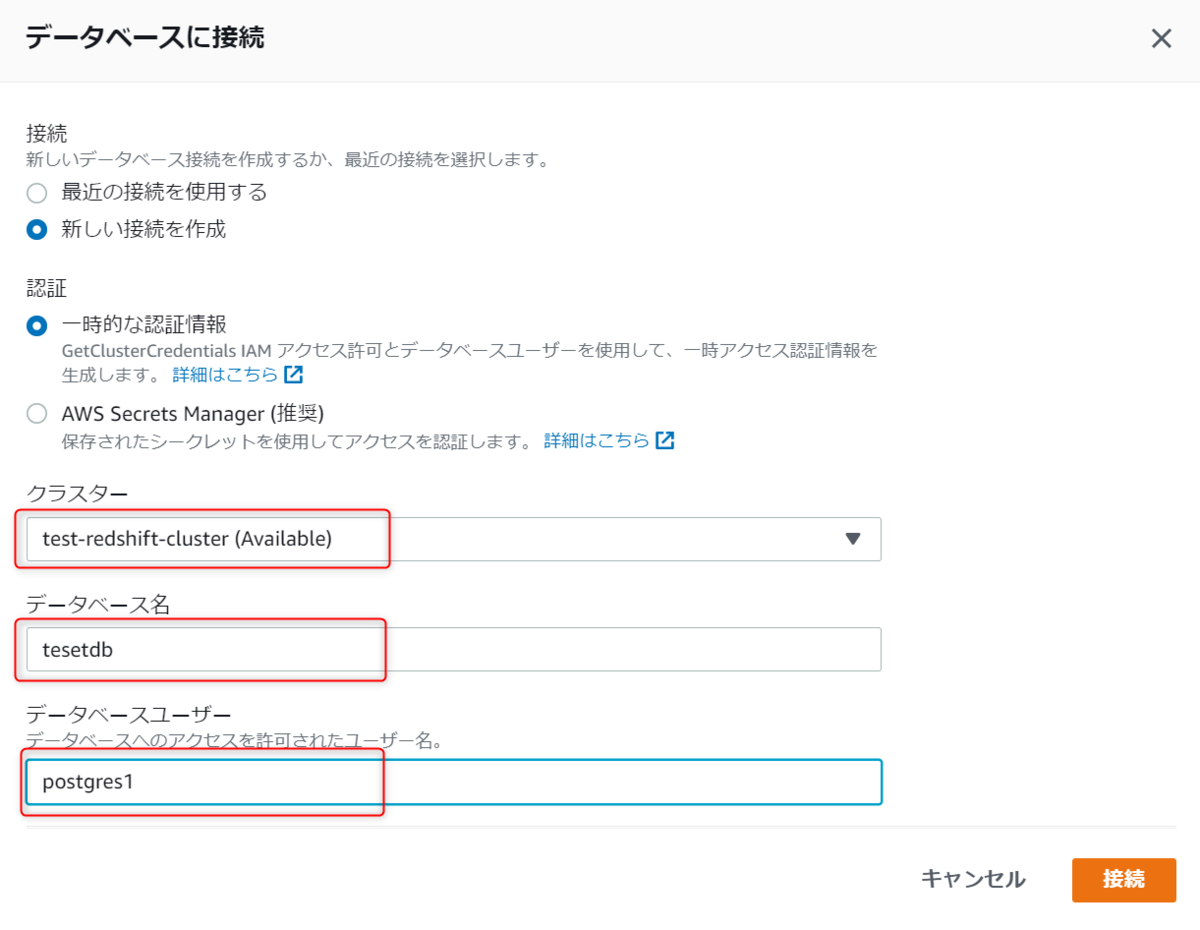
クラスター、データベース名、データベースユーザーを入力して接続を押下します。
SSMを使用して接続もできますが、今回は直接入力します。
無事接続ができると左側にテーブル名が表示されます。
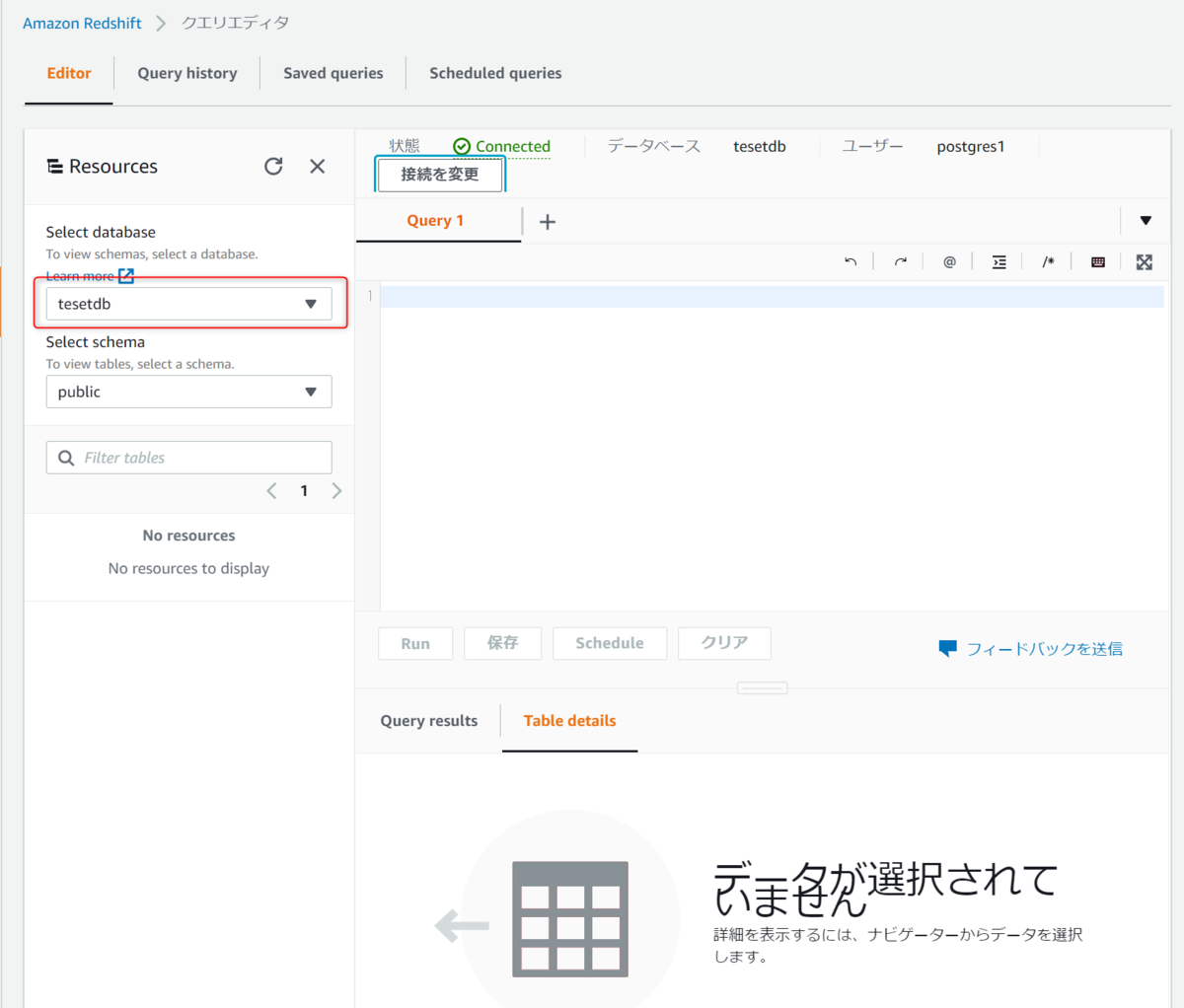
以下のSQLを真ん中のエディタに入力して実行してみます。
create table shoes(
shoetype varchar (10),
color varchar(10));insert into shoes values
('loafers', 'brown'),
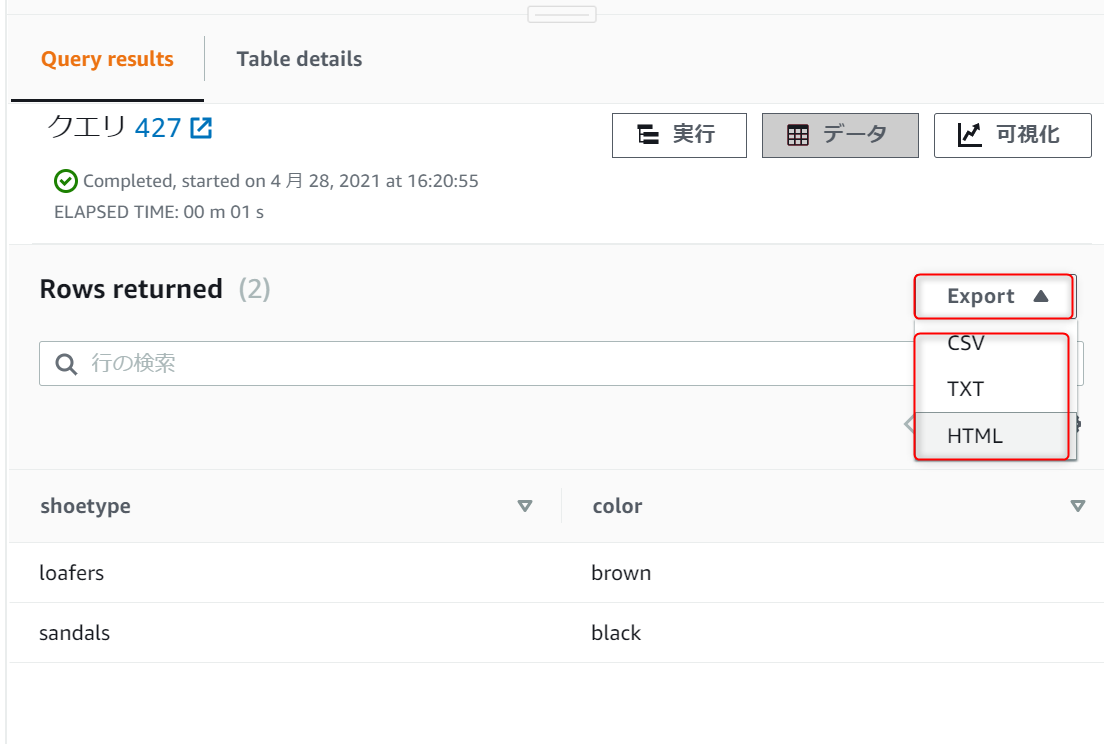
('sandals', 'black');select * from shoes;
最後のselectで取得された結果がRows returnedに表示されています。

表示された結果はファイルとしてダウンロードが可能です。
ステップ 6: Amazon S3 のサンプルデータをロードする
次はS3からRedshiftにデータをロードしてみます。
まずはSQLを実行してテーブルを作成します。
SQLは数が多いので以下リンクにあるものを上から順番に実施します。
docs.aws.amazon.com
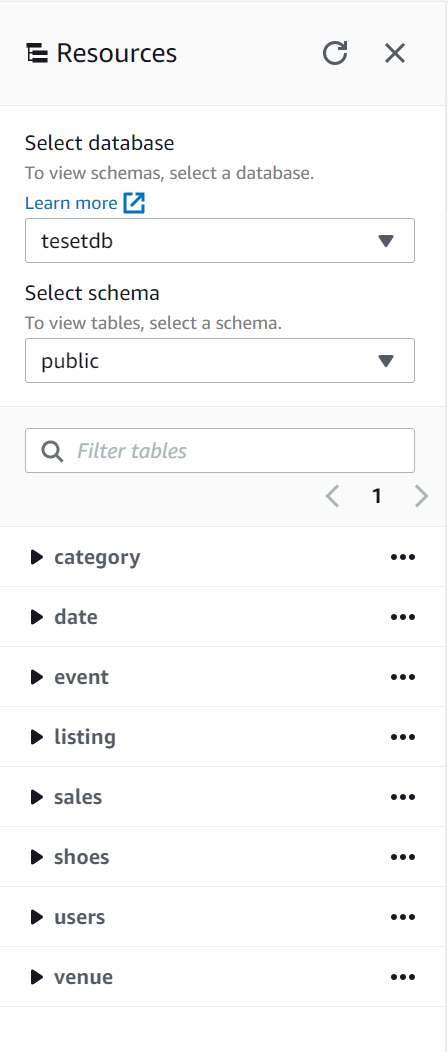
実行が完了するとテーブルが以下のように作成されていることが確認できます。
サンプルファイルをダウンロードします。
https://docs.aws.amazon.com/ja_jp/redshift/latest/gsg/samples/tickitdb.zip
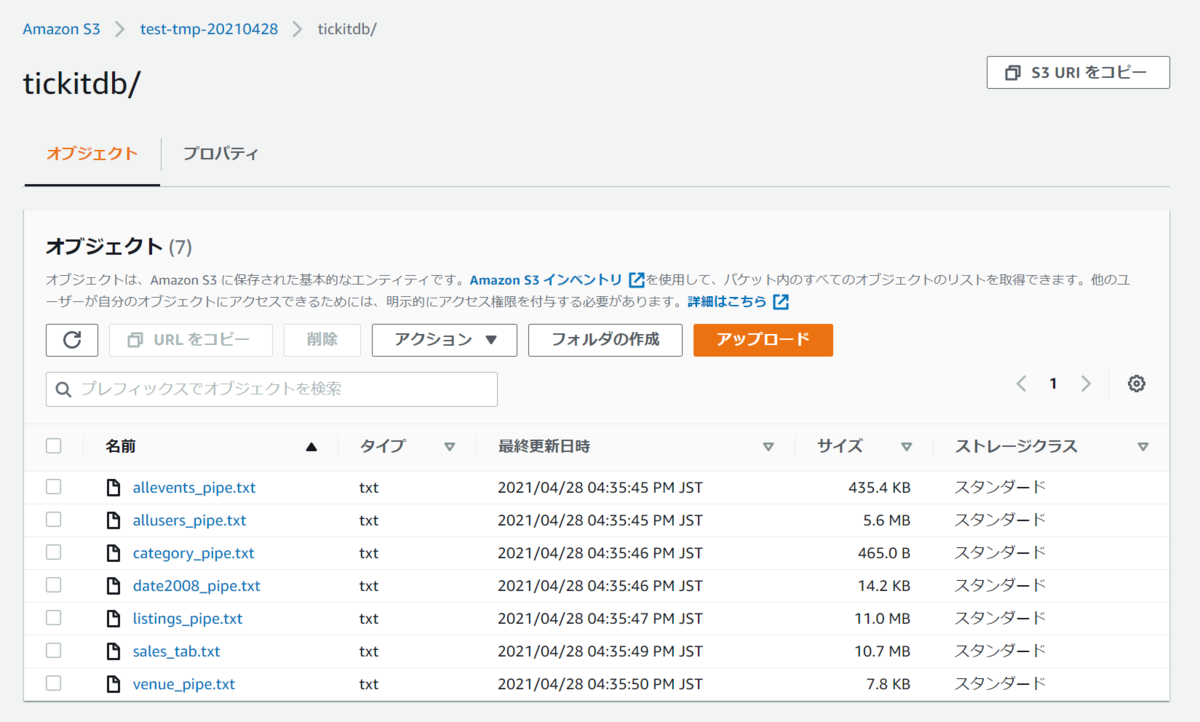
ファイルを解凍して一時的に作ったS3バケットにアップロードします。
以下のリンクを確認して、S3上のファイルからRedshiftにロードするSQLを作成して実行します。
docs.aws.amazon.com
全部のSQLはここに書けないので一部だけ載せます。
IAMロールは事前に作成したロールのarnを設定します。
このSQLを実行してみます。
copy users from 's3://test-tmp-20210428/tickitdb/allusers_pipe.txt' credentials 'aws_iam_role=arn:aws:iam::XXXXXXXXX:role/testRedshiftRole' delimiter '|' region 'ap-northeast-1';
エラーで失敗しました。
ERROR: User arn:aws:redshift:ap-northeast-1:XXXXXXXXX:dbuser:test-redshift-cluster/postgres1 is not authorized to assume IAM Role arn:aws:iam::941996685139:role/testRedshiftRole
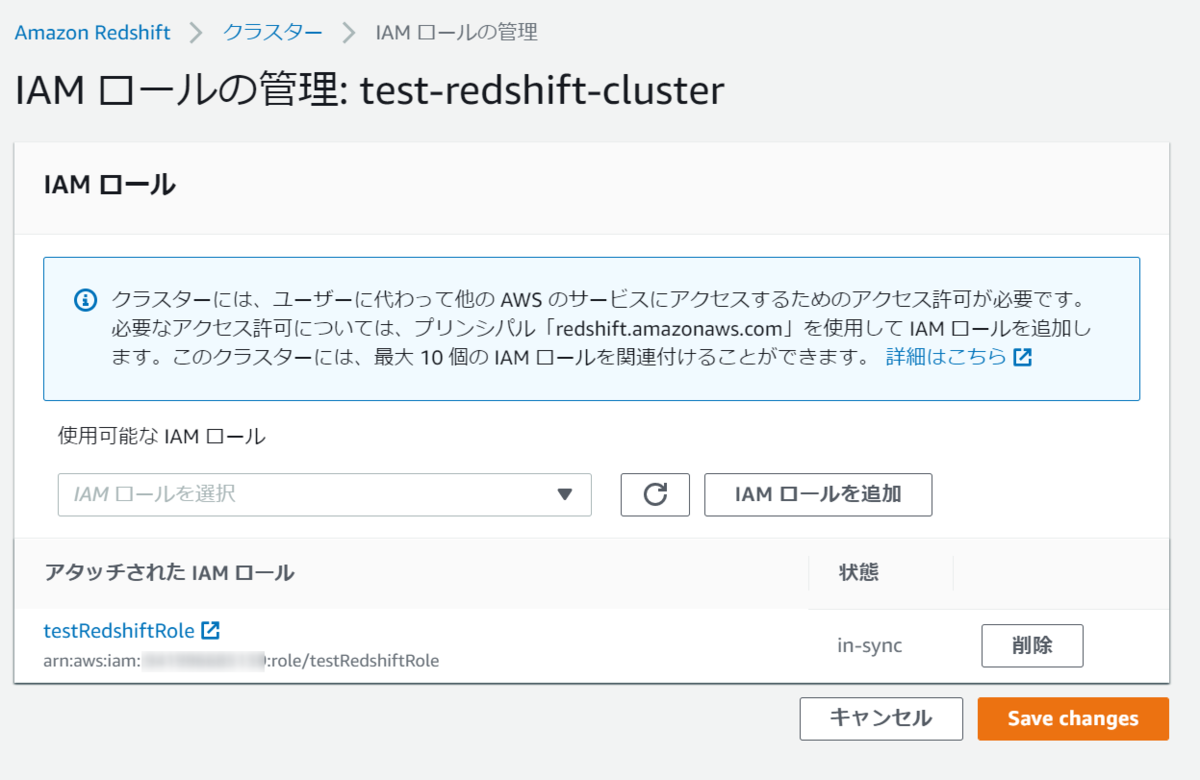
確認したところ、アタッチしたと思っていたIAMロールがアタッチされていないことがわかりましたので、手動で設定して再度SQLを実行します。
SQLが正常終了しました。
同じように他のSQLも実行していきます。
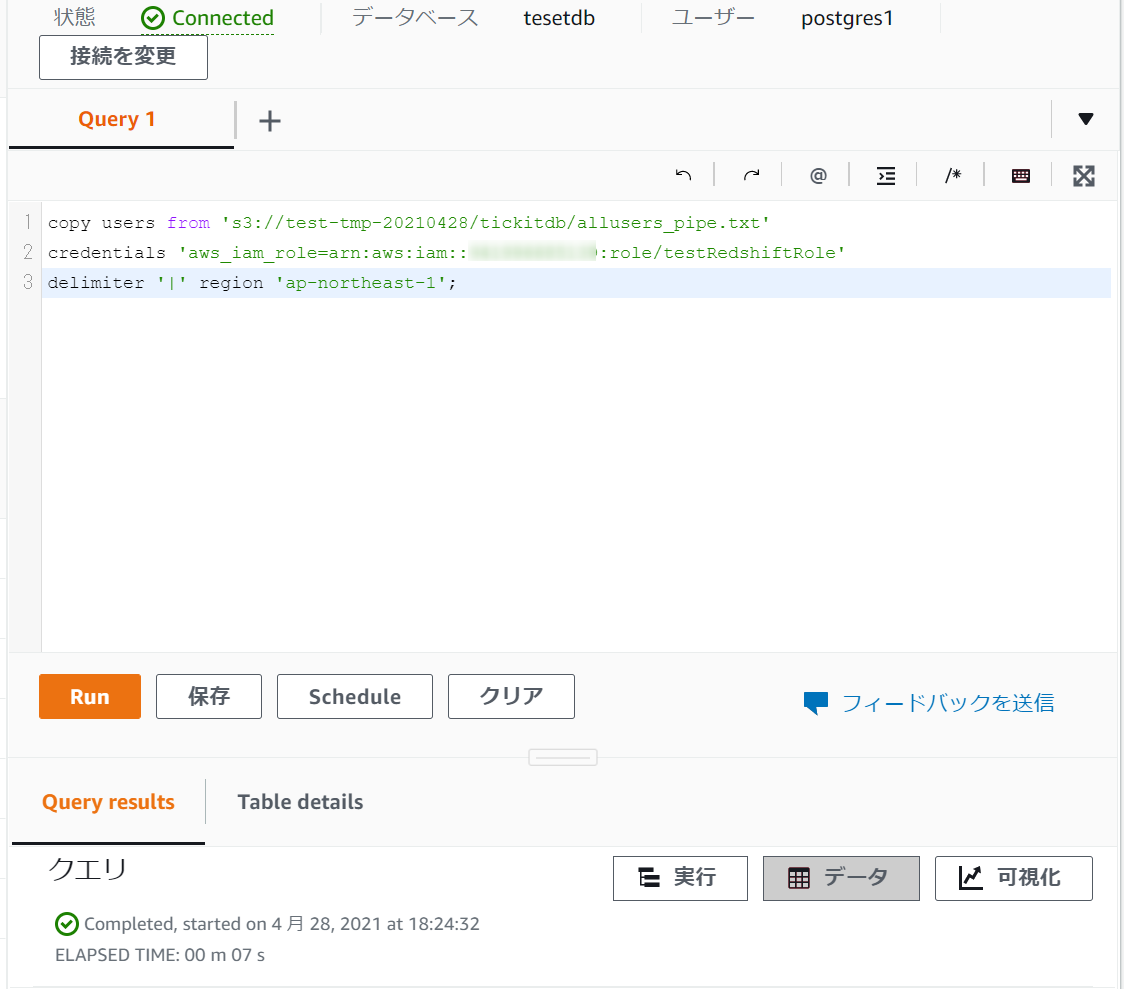
全部実行し終えたら次にいきます。
ステップ 7: クエリ例を試す
S3上のファイルから取り込んだデータに対して以下のリンクにあるSQLを実行して結果を取得します。
docs.aws.amazon.com
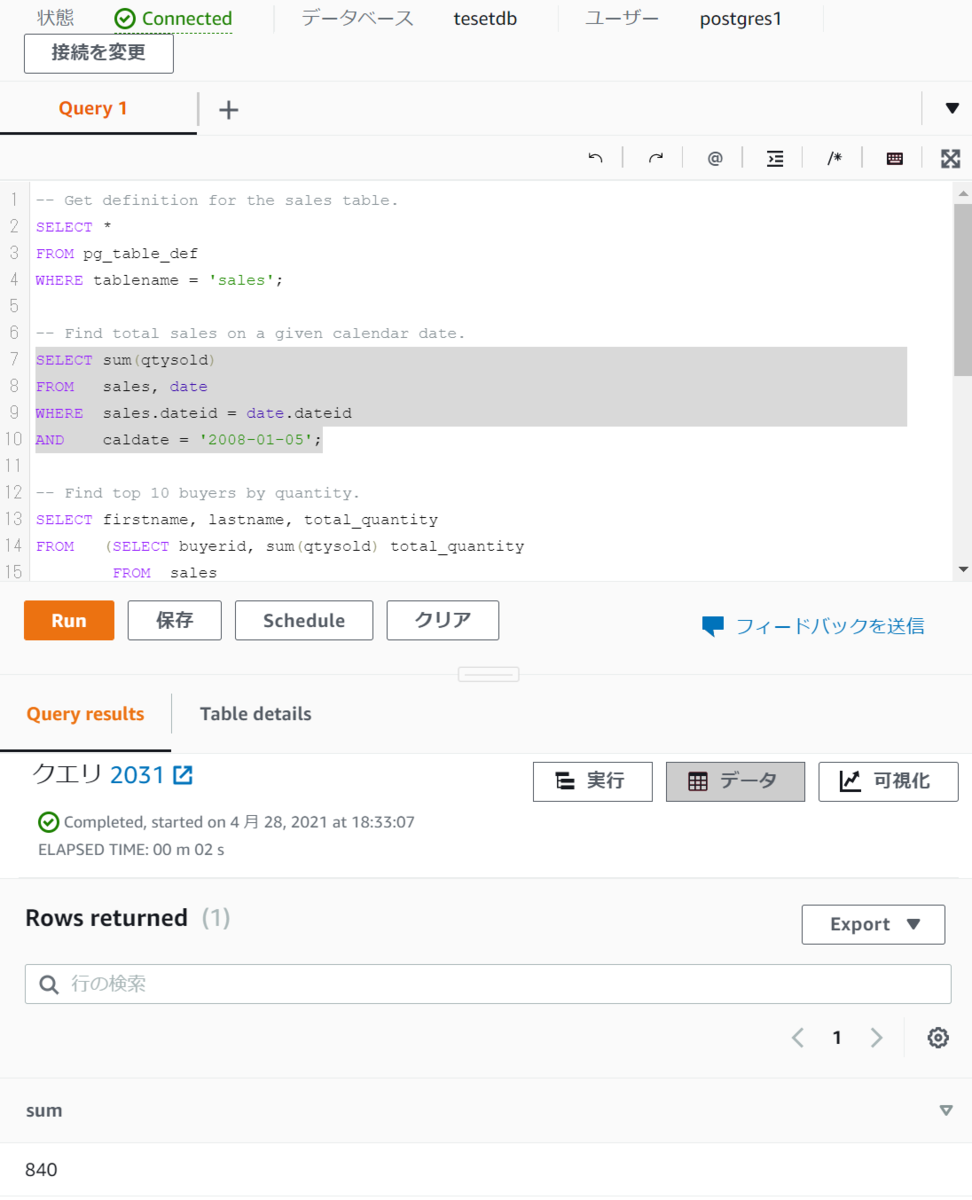
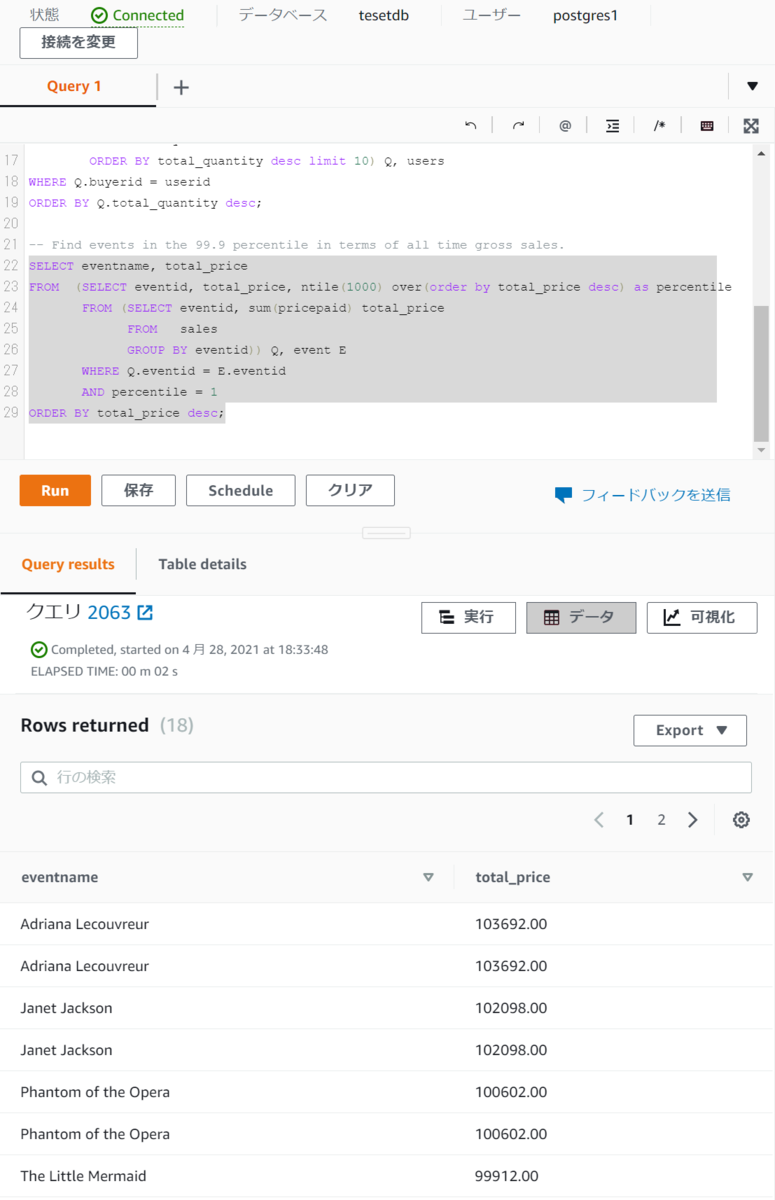
実際に実行した結果は以下です。
いずれも問題なくデータの取得ができました。
※何回かCOPYコマンドを実行したので複数入っているデータもあります。
その1

その2
その3

その4
感想及び所感
チュートリアルに従って実施するだけなので、比較的サッと終わるかと思いましたが、意外と詰まりどころが多くて時間かかりました。
構築系はコンソールからだとどうしても時間がかかってしまうので、検証用にCloudformationなどを使っていつでも構築できるようにしておいた方が良さそうです。