タイトル通りです。
具体的には以下のドキュメントに書いてある手順を実際に行っていきます。
Amazon S3 への DB スナップショットデータのエクスポート - Amazon Relational Database Service
データは以下の記事で準備したものを利用します。
RDSにCloudShellからアクセスしてみる - カピバラ好きなエンジニアブログ
実施作業
スナップショット取得
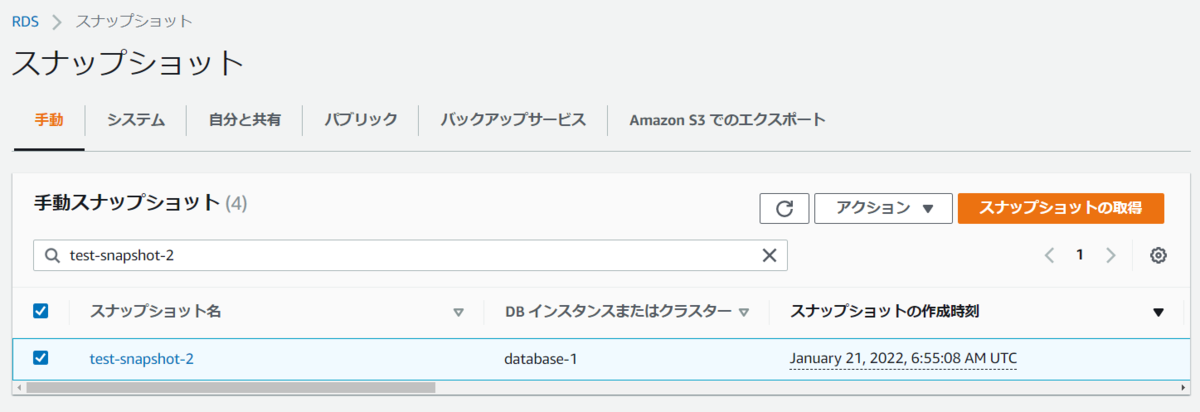
既にRDS上にサンプルデータは登録されているので、以下の過去記事を元に手動スナップショットを取得します。
Amazon RDS(PostgreSQL)の手動スナップショットを取得する - カピバラ好きなエンジニアブログ
スナップショット名はtest-snapshot-2にしました。
データエクスポート実行
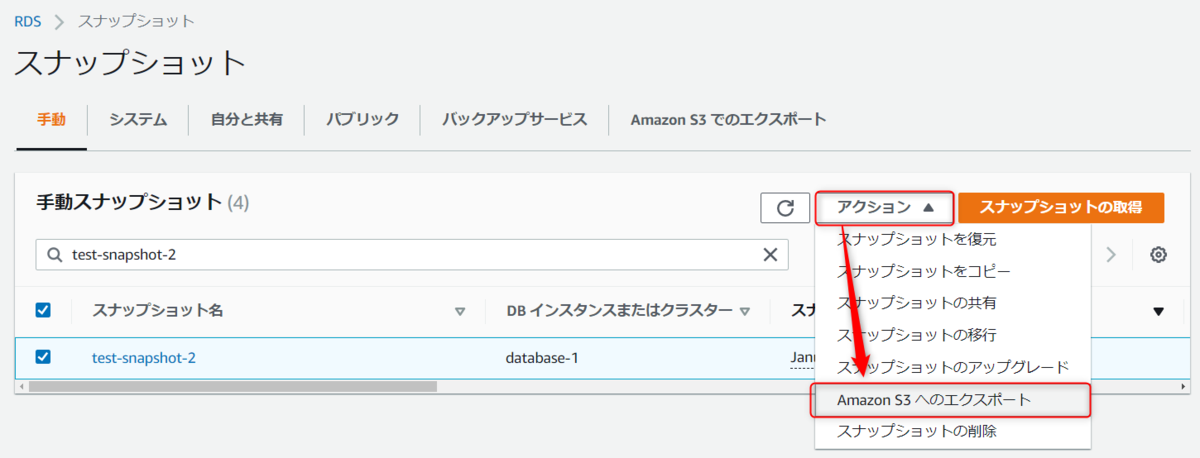
RDSのスナップショット画面から取得したスナップショット名を選択し、アクションからAmazon S3へのエクスポートを押下します。
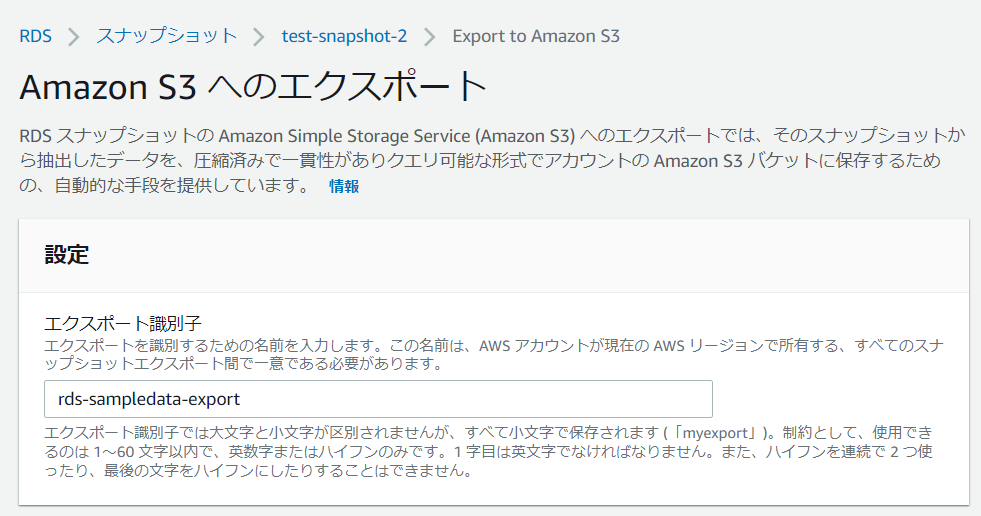
エクスポート画面に遷移するため、入力規則に従って識別子を入力します。
次にエクスポートデータと出力先を定義します。
エクスポート対象は識別子を利用して絞ることが可能ですが、今回はそこまでデータ量もないので全データをエクスポートします。
S3には先ほど作成したバケット名を指定します。
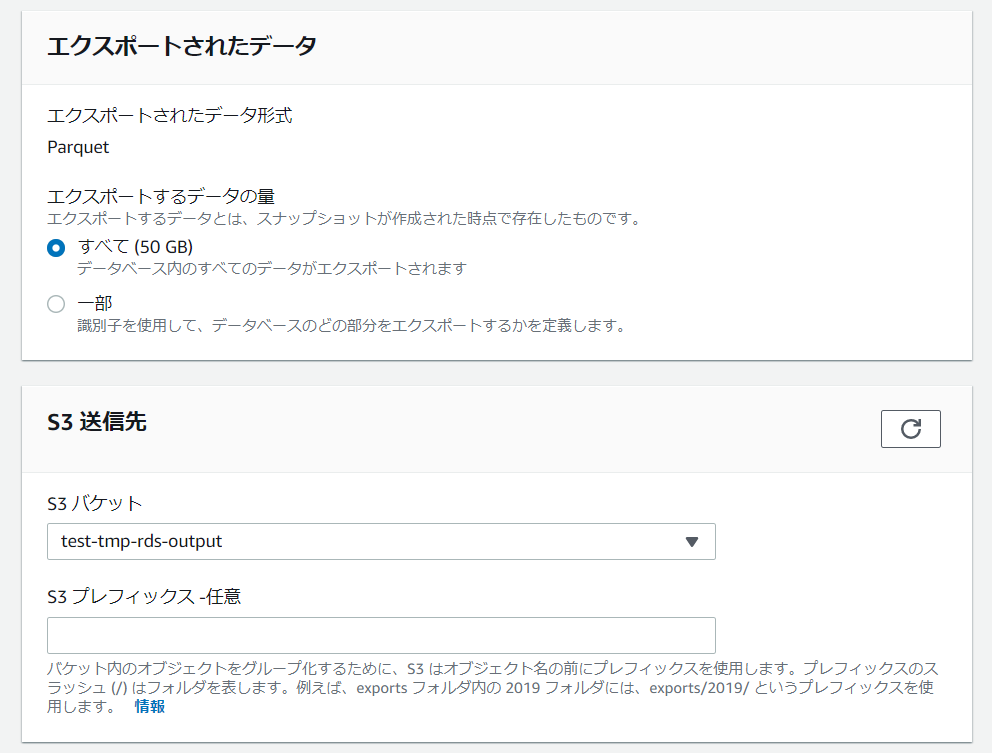
エクスポートタスクを代理実行するIAMロールと暗号化に使用するKMSキーを指定します。
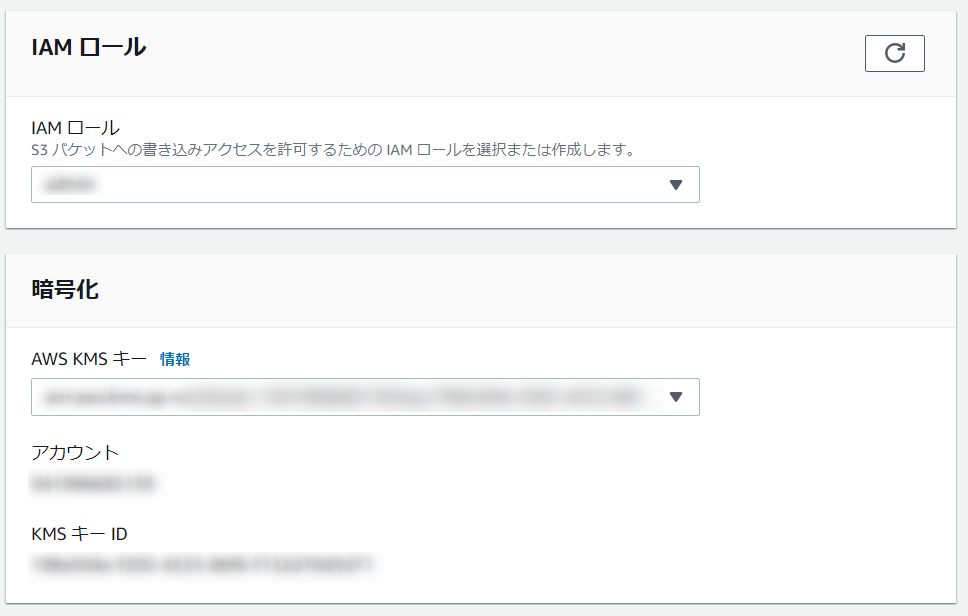
IAMロールには最低限必要な権限がありますので、それ等の権限を保有するロールを指定してください。

Amazon S3 への DB スナップショットデータのエクスポート - Amazon Relational Database Service
あとは以下のサービスをロールの信頼関係に追加しておく必要があるようです。
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "export.rds.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}'
ここまで入力できたらエクスポートボタンを押下します。
料金はサイズによるようなので、サイズの大きいスナップショットからエクスポートする場合はご注意ください。
エクスポートタスクが実行できると以下のようにステータスが起動中になります。
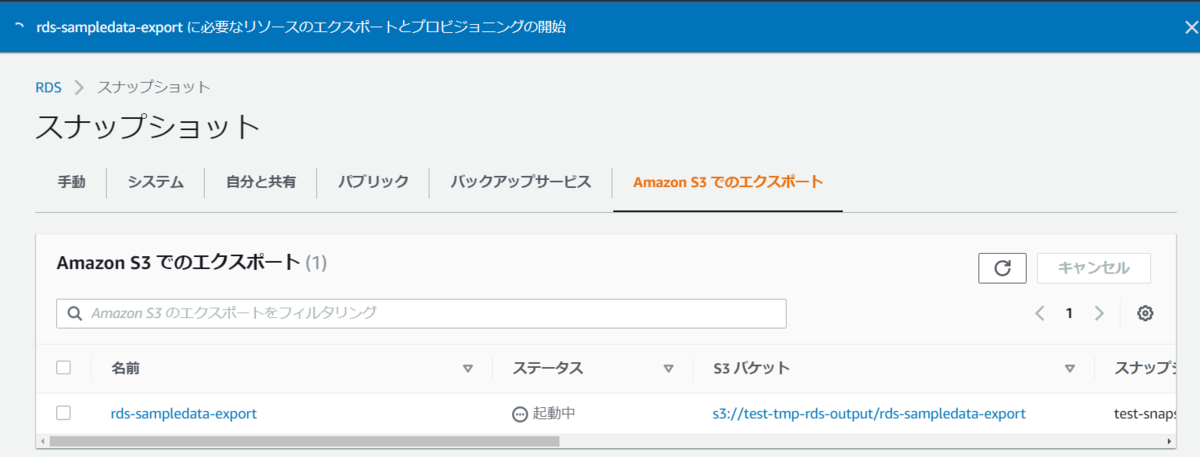
何故起動中かというと、以下のドキュメントに書いてある通り、一度スナップショットから復元が行われ、そのあとにエクスポートするような処理になっているため、バックグラウンドでデータベースの起動が行われているものと思います。
ちなみにコンソール上からはそういったリソースは確認できませんでした。

Amazon S3 への DB スナップショットデータのエクスポート - Amazon Relational Database Service
しばらく待つとステータスが完了になりました。
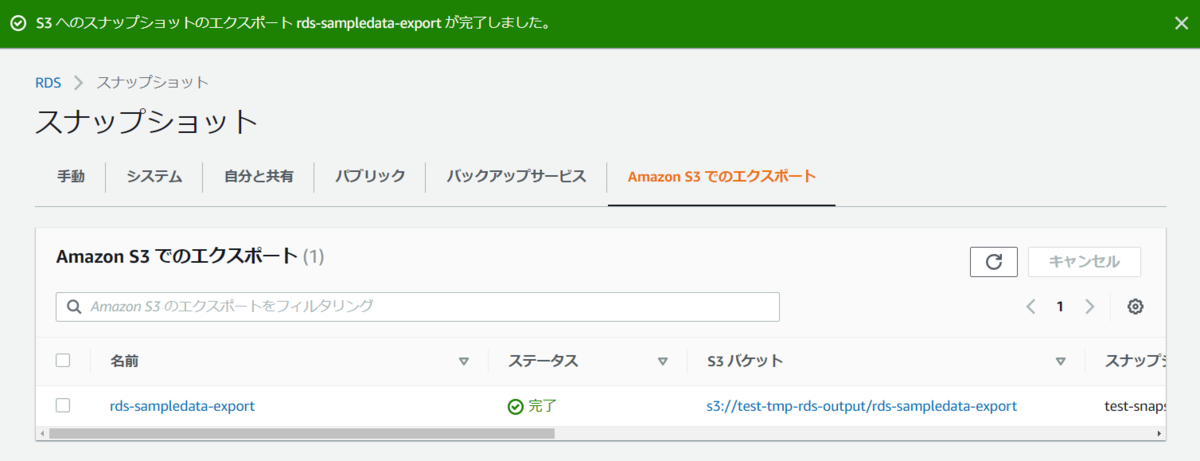
エクスポート結果確認
出力先のS3バケットを確認してみます。
rds-[DB名]-exportという名前のフォルダが作成されており、その中にはjsonファイルが2つとDB名のフォルダが1つ作成されていました。
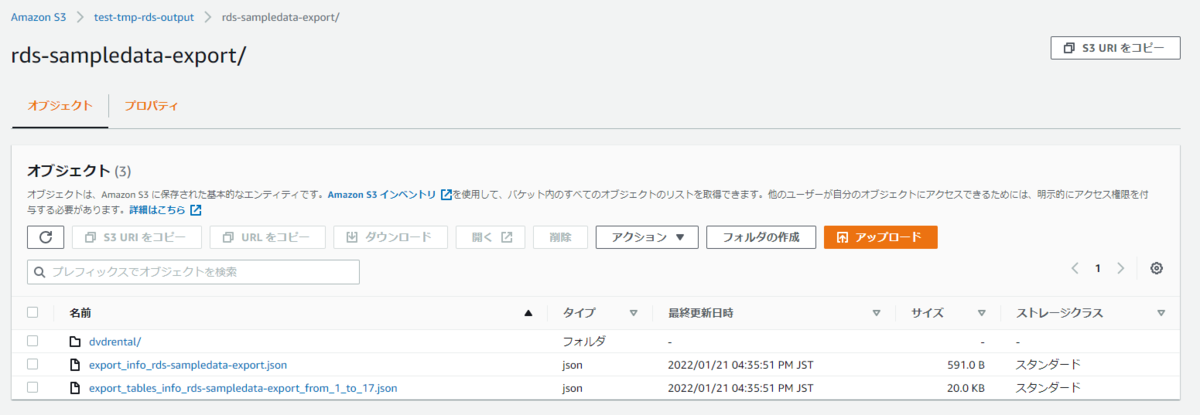
jsonファイルをS3 Selectで見てみると、1つのファイルにはエクスポートで設定した情報とエクスポート結果が記載されており、もう一つのファイルにはデータ型のマッピング情報が書いてありました。
export_info_rds-sampledata-export.json
{
"exportTaskIdentifier": "rds-sampledata-export",
"sourceArn": "arn:aws:rds:ap-northeast-1:123456789123:snapshot:test-snapshot-2",
"exportOnly": [],
"snapshotTime": "Jan 21, 2022, 6:54:55 AM",
"taskStartTime": "Jan 21, 2022, 7:33:04 AM",
"taskEndTime": "Jan 21, 2022, 7:35:49 AM",
"s3Bucket": "test-tmp-rds-output",
"s3Prefix": "",
"exportedFilesPath": "rds-sampledata-export",
"iamRoleArn": "arn:aws:iam::123456789123:role/xxxx",
"kmsKeyId": "arn:aws:kms:ap-northeast-1:123456789123:key/[ランダム文字列]",
"status": "COMPLETE",
"percentProgress": 0,
"totalExportedDataInGB": 0.012930341064929962
}
export_tables_info_rds-sampledata-export_from_1_to_17.json
{
"perTableStatus": [
{
"tableStatistics": {
"extractionStartTime": "Jan 21, 2022, 7:33:59 AM",
"extractionEndTime": "Jan 21, 2022, 7:34:10 AM",
"partitioningInfo": {
"numberOfPartitions": 1,
"numberOfCompletedPartitions": 1
}
},
"schemaMetadata": {
"originalTypeMappings": [
{
"columnName": "actor_id",
"originalType": "integer",
"expectedExportedType": "int32",
"originalCharMaxLength": 0,
"originalNumPrecision": 32,
"originalDateTimePrecision": 0
},
{
"columnName": "first_name",
"originalType": "character varying",
"expectedExportedType": "binary (UTF8)",
"originalCharMaxLength": 45,
"originalNumPrecision": 0,
"originalDateTimePrecision": 0
},
~省略~
DB名フォルダ配下には[スキーマ名].[テーブル名]のフォーマットでフォルダがあり、テーブル名フォルダ配下にはparquetファイルとエクスポート結果が書かれたオブジェクトが格納されていました。
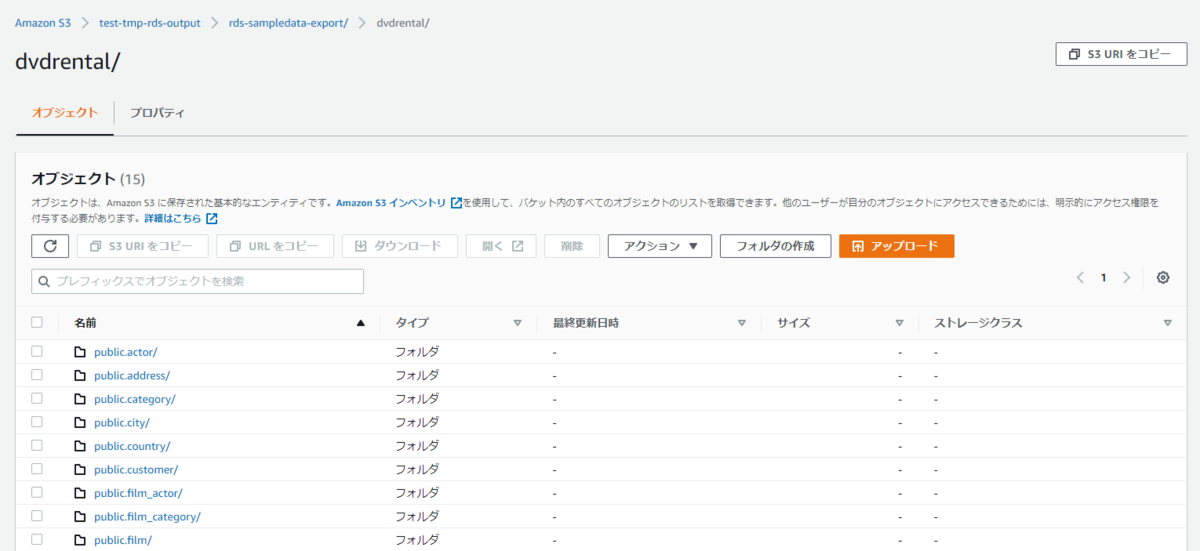
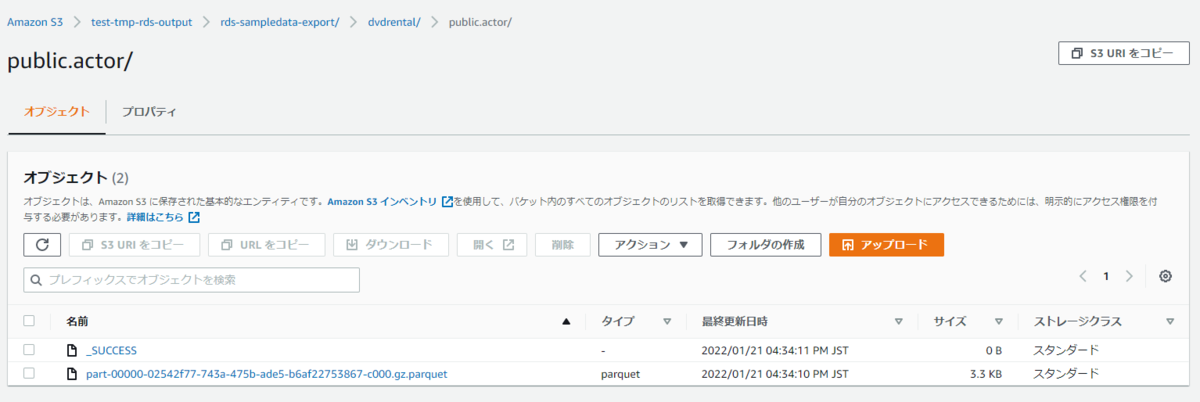
ParquetファイルをS3 Selectで見るとデータが確認できるので、エクスポートは問題なく成功しているようです。
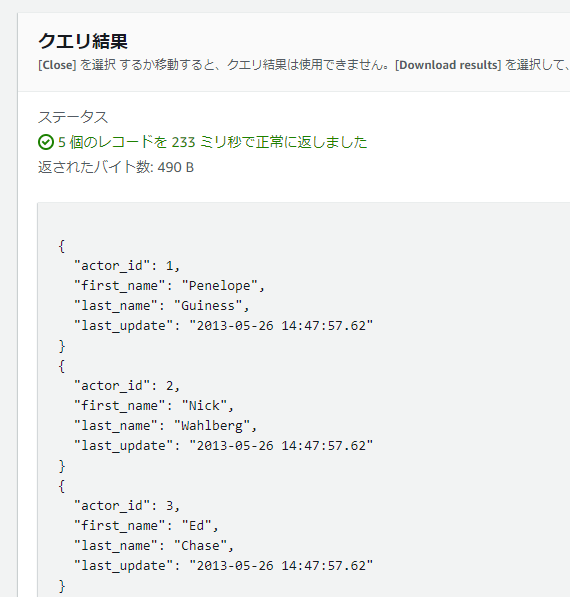
データエクスポート実行(2回目)
同じ出力先にもう一度エクスポートしたらどうなるか気になったので、再度エクスポートを実行してみます。
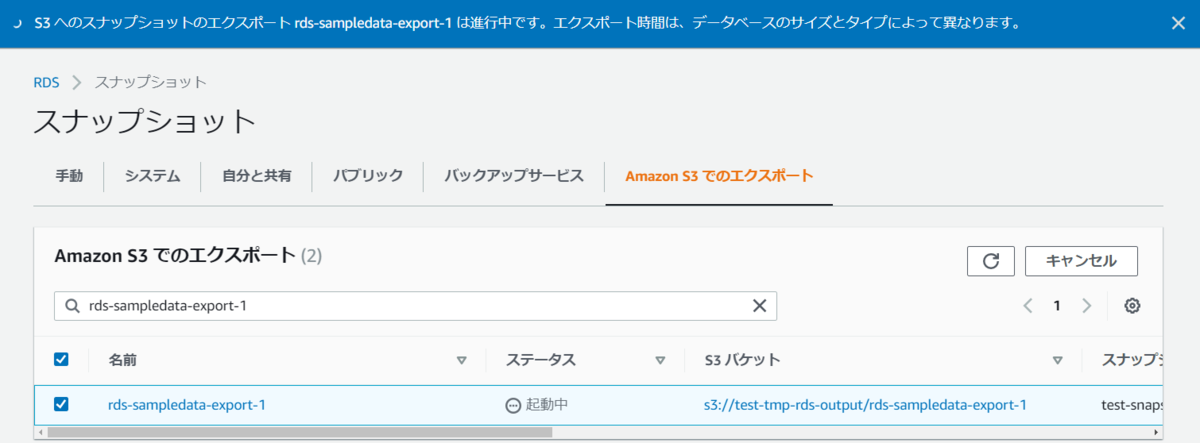
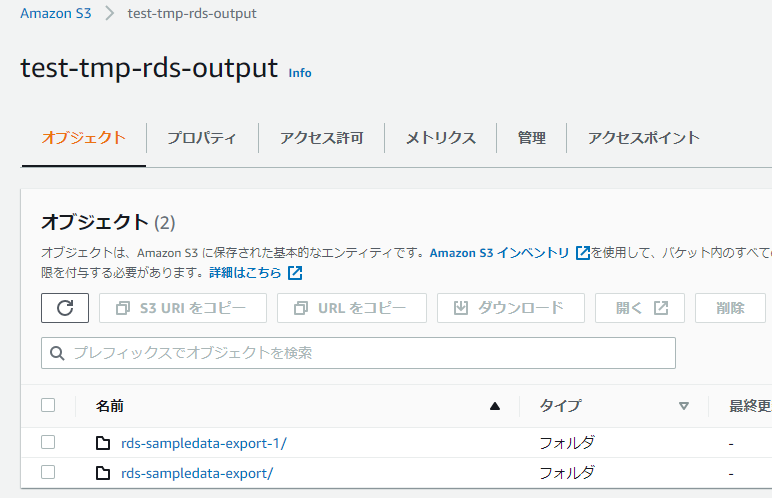
S3を確認するとエクスポートの識別子でフォルダが分かれるようなので、同じフォルダに上書きはできないようです。
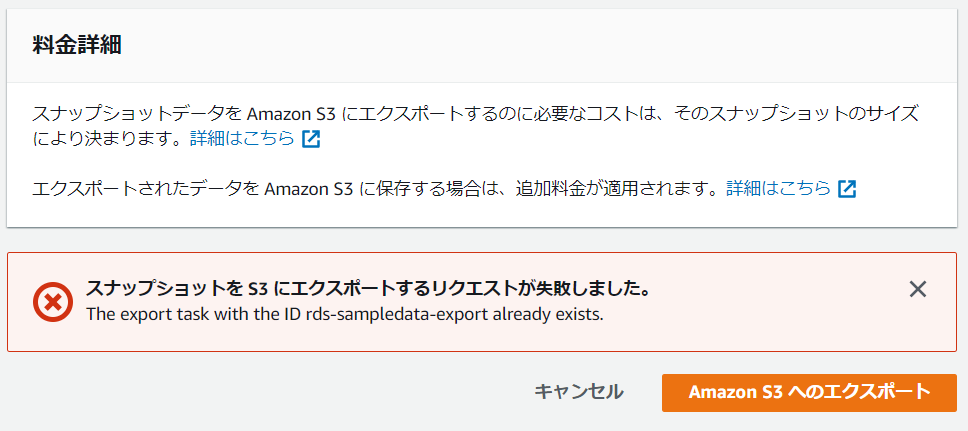
同じエクスポート識別子で作成しようとするとエラーが出たので、やはり同じ出力先にエクスポートするのは無理そうです。
感想及び所感
一時的にRDSのデータをS3に出力させるのであれば、このエクスポート機能が使えそうです。
ただ、定期的な出力をしようと思うと識別子名に実行日付を含めて日付ごとにエクスポートするなどの工夫が必要なので、実務で利用する際は考慮が必要だと感じました。