AWSにはSaaSサービスからのデータ連携を簡単に行うためのAmazon AppFlowというサービスがあります。
設定項目としてはそこまで多くはないので、整理も兼ねて実際のコンソールからの設定項目を確認します。
aws.amazon.com
尚、設定には送信元と送信先の設定が必要なので、今回は送信元にSalesforce・送信先にS3を指定します。
AppFlowとは
ドキュメントには以下のように記載されています。
Salesforceなどのサービスとしてのソフトウェア(SaaS)アプリケーションと、Amazon Simple Storage Service(Amazon S3)やAmazonRedshiftなどのAWSサービスとの間でデータを安全に交換できるようにするフルマネージド統合サービスです。
簡単に言うと、SaaSサービスのデータをAWSサービスに簡単に取り込むことができるマネージドサービスです。
またSaaSサービスだけではなくて、S3からS3みたいなこともできたりします。
フルマネージドで提供されるので、ユーザはインフラの管理などを考えずにデータ連携とデータ管理に集中することができます。
設定項目確認
管理項目
マネコンからAppFlowのコンソールに移動してみると、まず4つの管理項目が確認できます。

・コネクタ
コネクタはAppFlowと連携するSaaSサービスが一覧で表示されます。

2021/12/3時点で送信元に設定可能なコネクタは次の16サービスです。
- Amazon S3
- Amplitube
- Datadog
- Dynatrace
- Google Analytics
- Infor Nexus
- Marketo
- Salesforce Pardot
- SAP OData
- Salesforce
- ServiceNow
- Singular
- Slack
- Trend Micro
- Veeva
- Zendesk

2021/12/3時点で送信先に設定可能なコネクタは次の9サービスです。
- Amazon Redshift
- Amazon S3
- Amazon EventBridge
- Amazon Lookout for Metrics
- Marketo
- Salesforce
- Snowflake
- Upsolver
- Zendesk
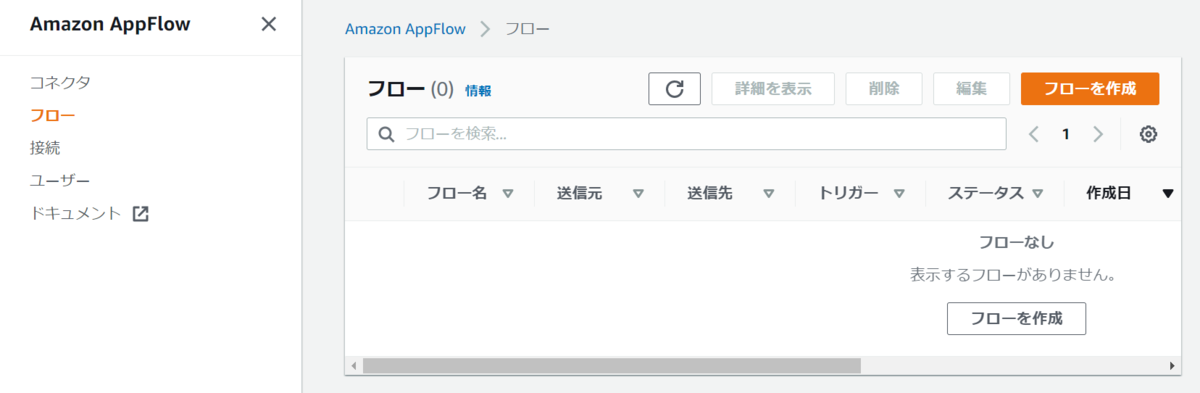
・フロー
フローにはデータを取得・変換・出力する一連の流れをノンコーディングで実装することができます。
データの送信元・送信先やその種類によって複数のフロー作成が必要になることもあります。
・接続
接続にはAppFlowと接続を行うサービスの接続情報や認証情報を登録できます。
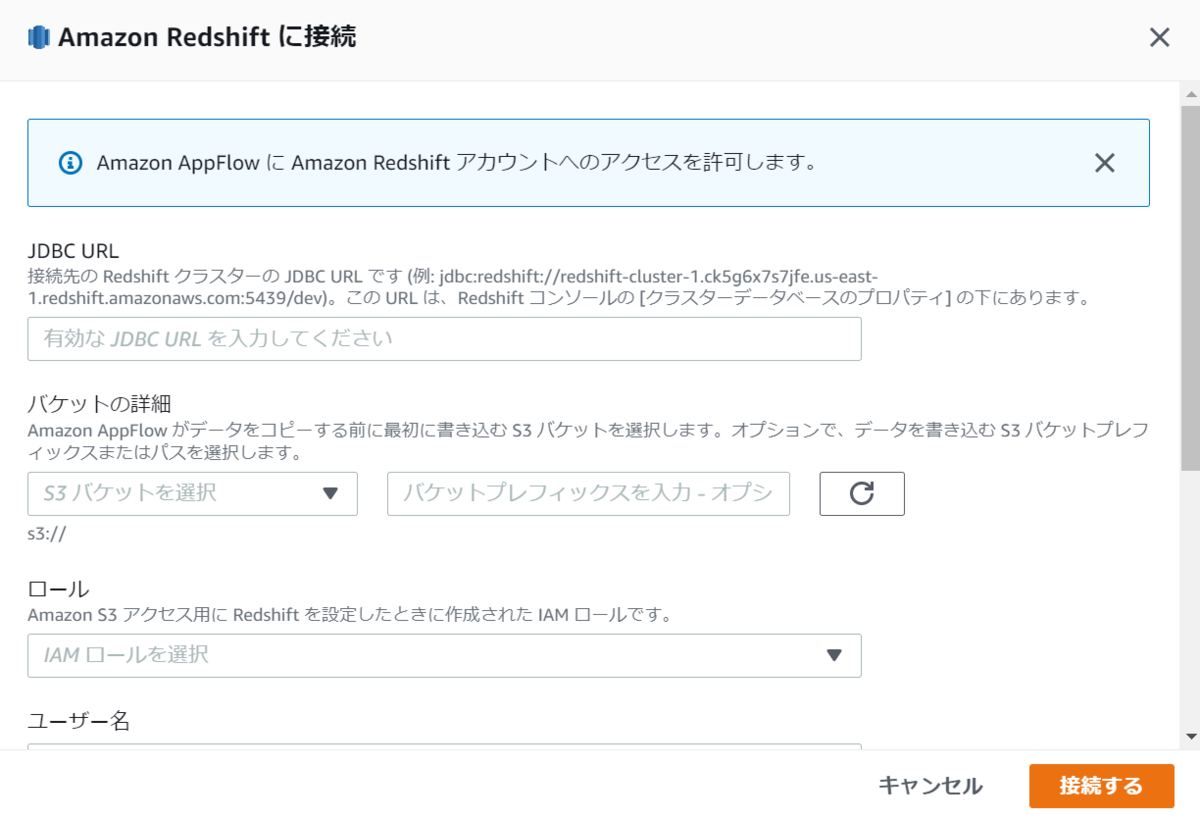
サンプルとしてRedshiftの接続作成時の画面を載せますが、このように接続に必要なJDBC URLやAppFlowが利用するS3の情報、ユーザ名やパスワード等が登録可能です。
これらの情報はAWSが管理します。
作成後は詳細な接続情報を確認することはできず、最低限の接続名・接続モード・URL・更新日等が一覧に表示されます。
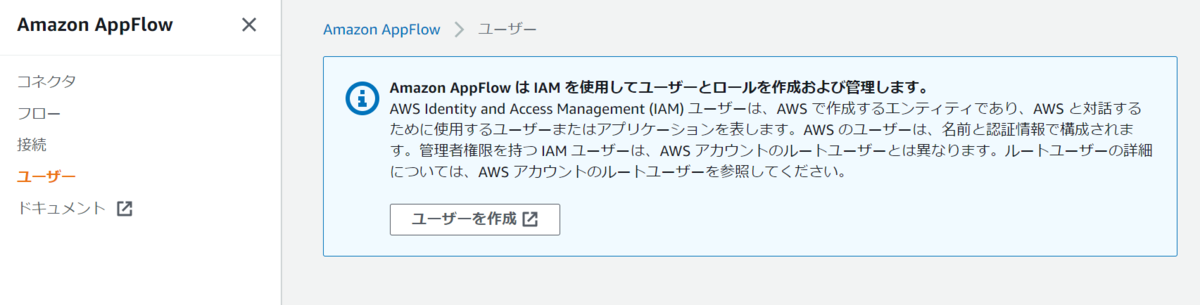
・ユーザ
ユーザにはAppFlowがIAMを利用してユーザー・ロールを管理するメッセージが表示されています。
これはまだよくわかっておりません。
フロー作成
一通り確認したところで実際にフローを作成しながら設定内容を見ていきます。
まずはフローの管理項目からフローの作成を押下します。
フローのセットアップの流れとしては次の4つで行うようです。
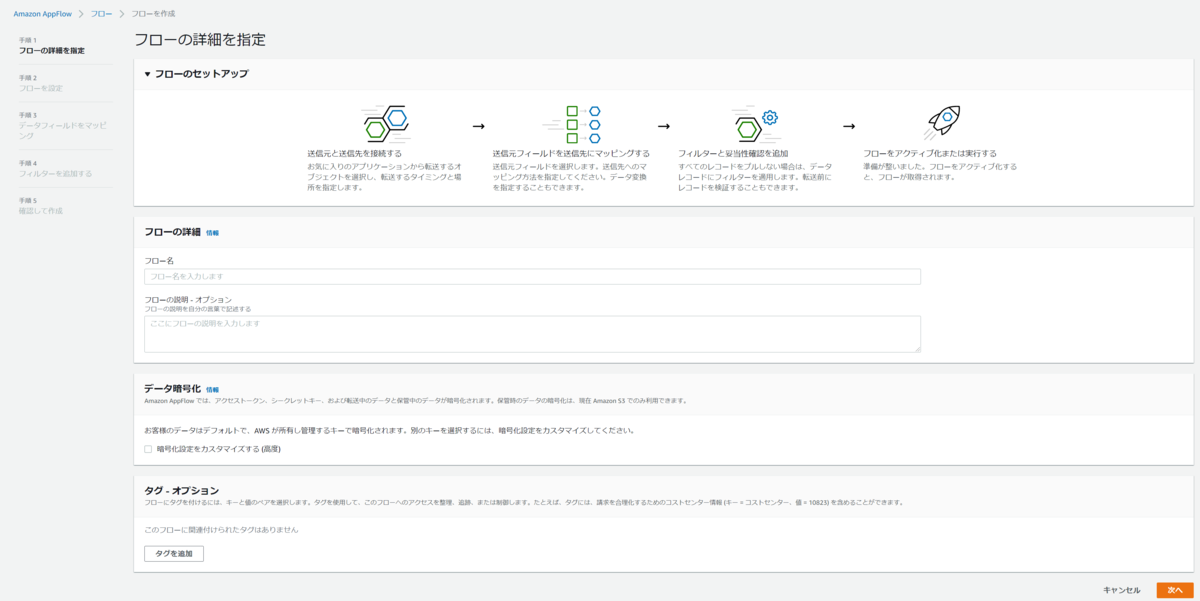
最初の設定画面では
- フローの名前と説明(説明はオプション)
- データ暗号化設定
- タグ(オプション)
の3つを設定します。
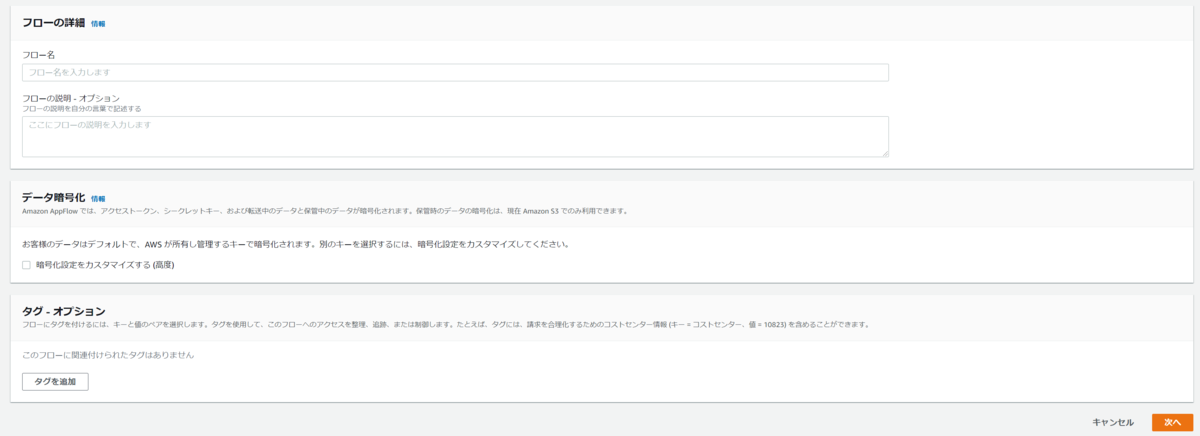
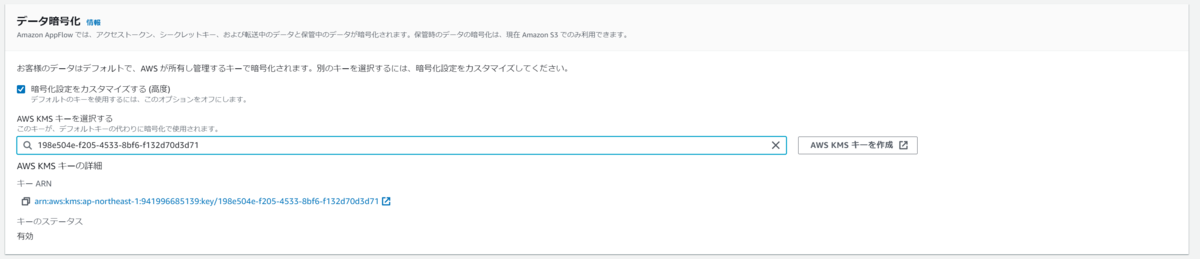
データ暗号化でカスタマイズにチェックをつけると、AWS KMSに作成しているキーが選択できます。
デフォルトではAWS管理のキーが利用されますが、セキュリティ要件でAWS KMSに登録されたキーを利用したい場合は設定が必要です。(別途KMSの料金が発生します
尚、デフォルトのキーまたはKMSキーのどちらを利用した場合でも、AppFlowでは
- アクセストークン
- シークレットキー
- 転送中データ
- 保管中データ(S3のみ)
が暗号化されるようになっています。
送信元と送信先を接続する
それではフローを作成していきます。
この設定では送信元と送信先の設定を行います。
今回のケースでは前回の記事で作成したSalesforceの開発環境に接続します。
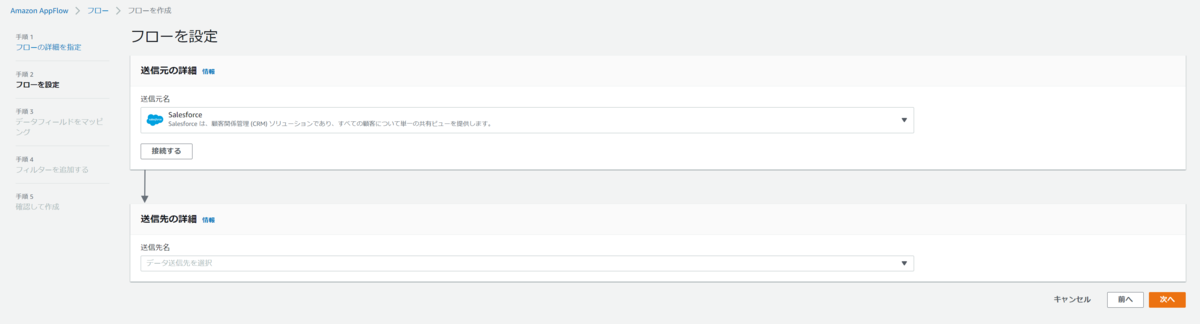
・送信元設定
送信元名にSalesforceを選択し、接続するを押下します。
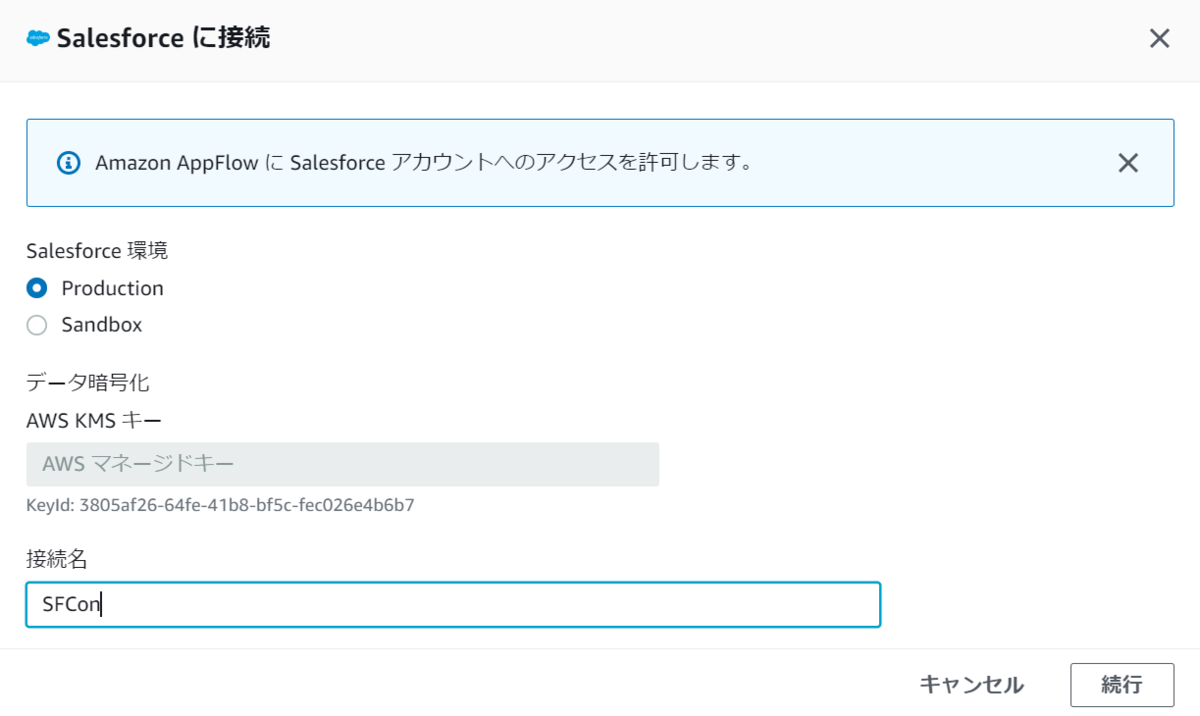
Salesforceに接続する画面が出てくるので、環境と接続名を設定して続行を押下します。
Salesforceの接続ウィンドウが表示されるので、事前に登録したユーザ名とパスワードを入力します。
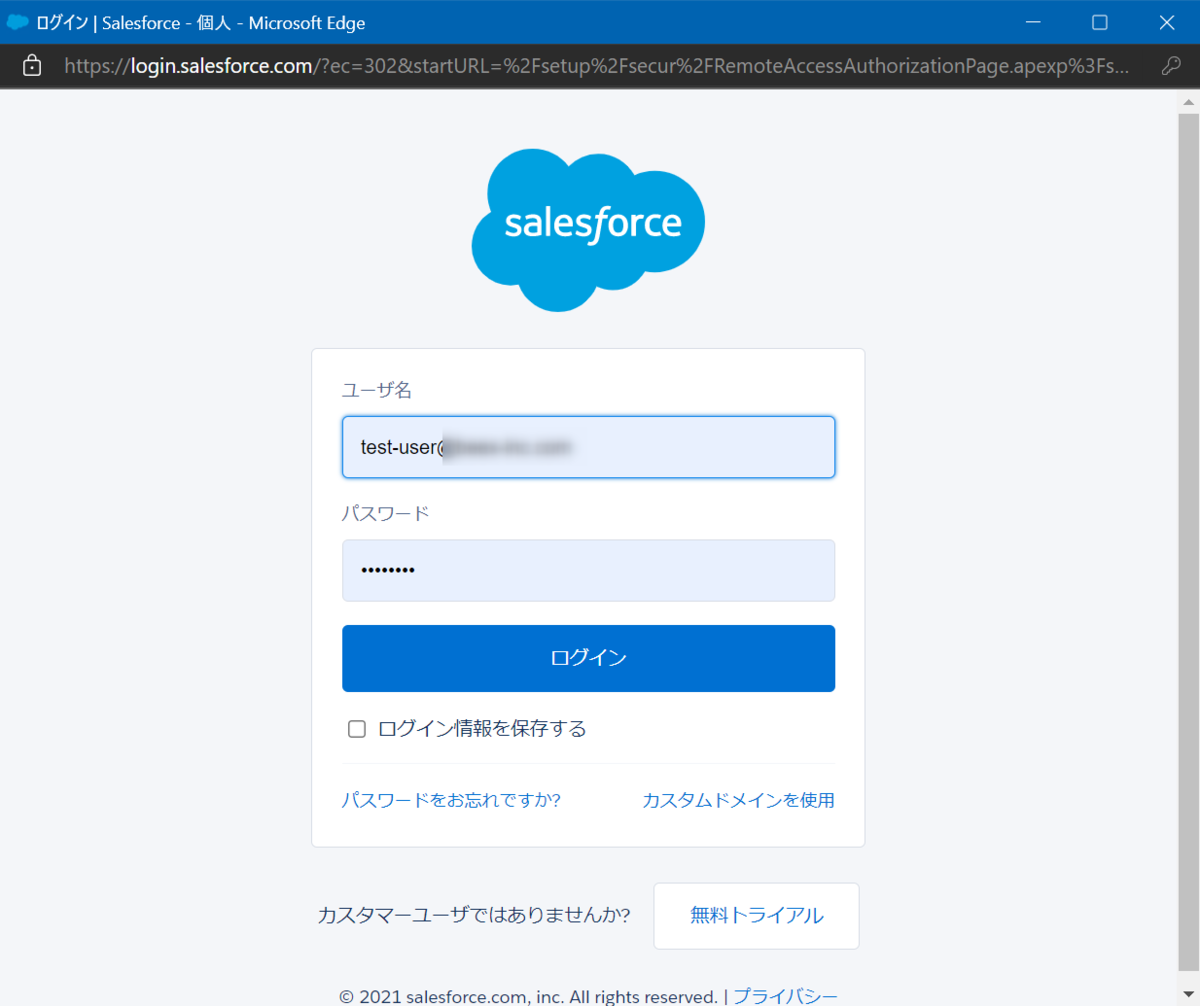
許可します。
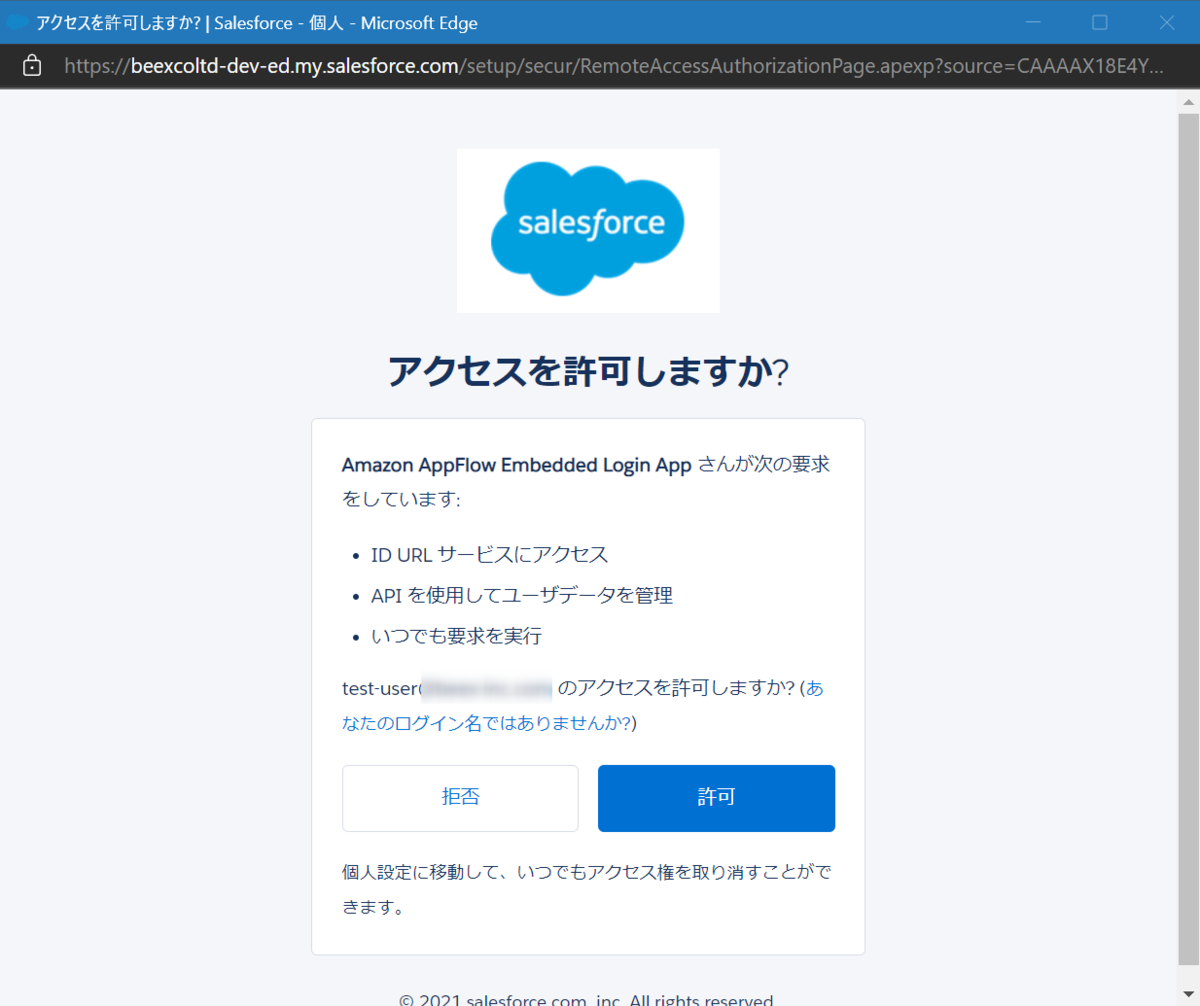
無事に送信元との接続が完了しました。
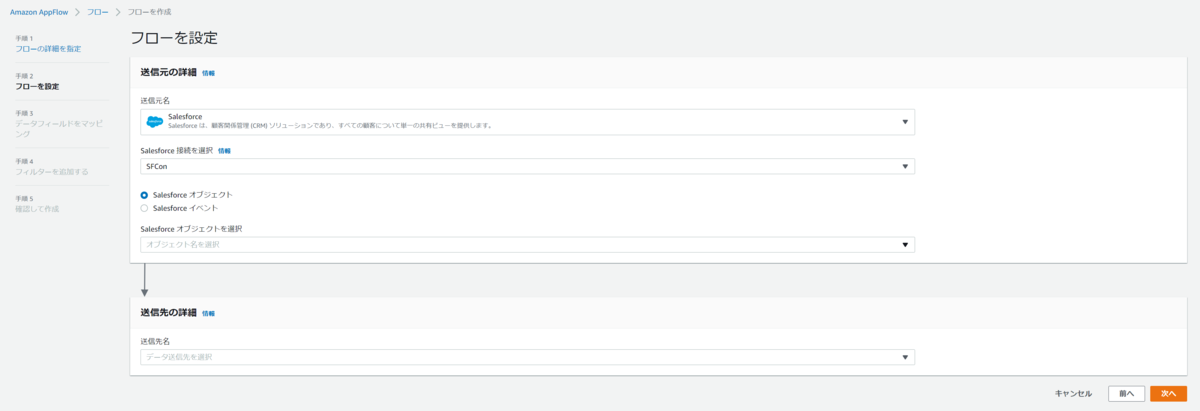
Salesforceの場合はオブジェクトとイベントの情報を取得できるようになっています。
リストから取得するオブジェクト、またはイベントを選択できます。
- Salesforceオブジェクト
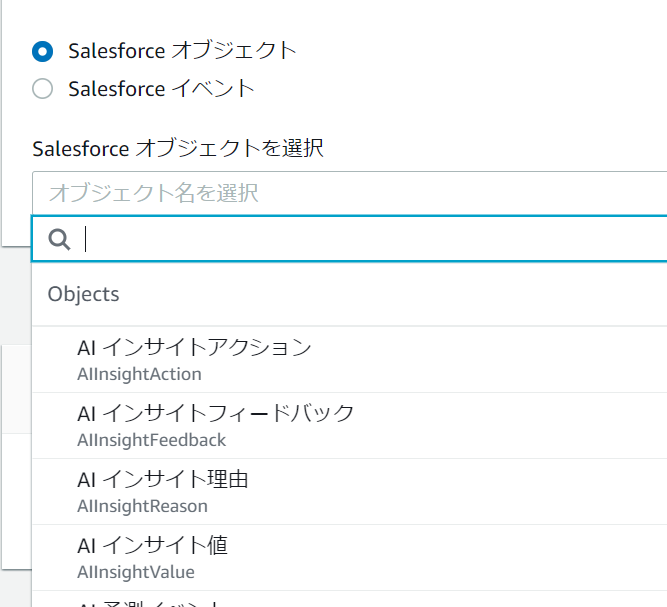
- Salesforceイベント

・送信先設定
送信先名にS3を選択し、出力するS3バケットの名前とプレフィックスを設定します。
S3に出力する際のパスは、S3バケット/指定したプレフィックス/フロー名/時間、という階層上になるように設定されます。(時間は後述のフォルダ構造設定を指定時のみです)

追加設定として、以下の4つが設定可能です。要件によって合うものを設定します。
- データ形式の設定:JSON/CSV/Parquet
- データ転送設定:すべてのレコードを集約/集約なし
- ファイル名の設定:ファイル名にタイムスタンプを追加する/タイムスタンプなし
- フォルダ構造の設定:タイムスタンプが付いたフォルダにファイルを配置する/フォルダにタイムスタンプを付けない

S3に出力したファイルをAthena等でクエリしたいということであればParquet形式が良いですし、ファイル名の重複を避けるのであればファイル名にタイムスタンプを追加します。
出力するファイル名を指定する項目はないため、固定のファイル名にするのは無理そうです。
・フロートリガー設定
送信元と送信先の設定ができたらフローをトリガーする設定を行います。

トリガー方法はオンデマンド・スケジュール・イベントの3つを選択することができます。
オンデマンドはその名の通り手動実行です。
スケジュールは頻度・開始終了日時・転送モードを設定することができ、転送モードでは完全転送と増分転送が選択できます。
増分転送にはタイムスタンプフィールドを使用するので、取得元のデータにタイムスタンプフィールドが含まれている必要があります。
また、フローの実行とデータの取り込み時間が同時に行われると正常にデータが取得できない可能性があるため、その時間を調整するための時間オフセットを指定できます。
この項目を指定することで、フローの実行時間に近いレコードを取り込み対象外とします。
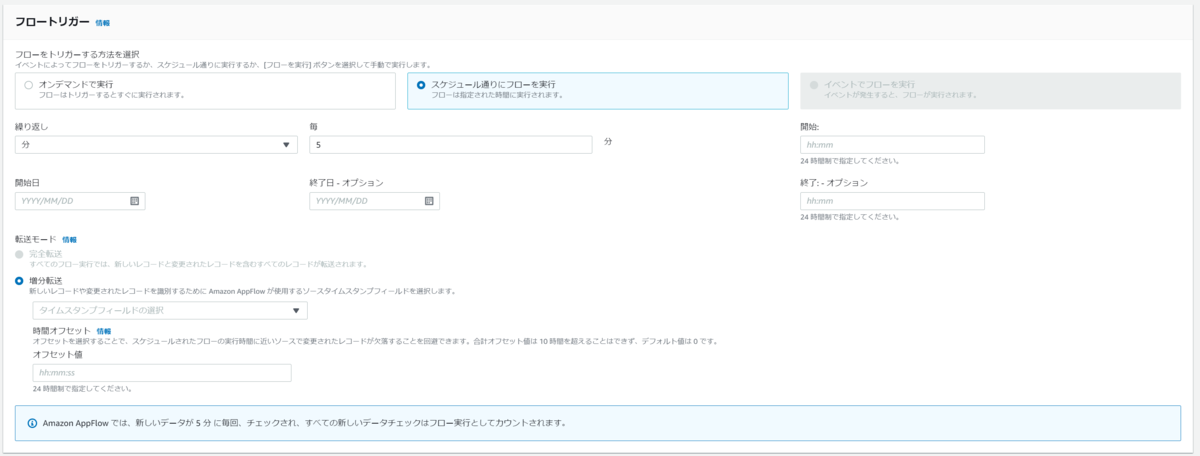
イベントは恐らくS3アップロードイベントなどをキャッチしてフローを実行できるような仕組みではないかと思いますが、今回のケースでは非活性になってますので割愛します。
送信元フィールドを送信先にマッピングする
フローの設定ができたら、次に取得元データフィールドと送信先フィールドのマッピング設定を行います。
マッピングは手動かCSVによる一括マッピングを選択できます。
フィールドが多い場合はCSVの利用をお勧めします。

手動マッピングでは、先ほど接続した取得元から既にフィールド情報が取得されているため、それをベースにマッピングを設定します。
ここではすべてのフィールドをマッピングすることもできますし、特定のフィールドのみをマッピングすることもできます。
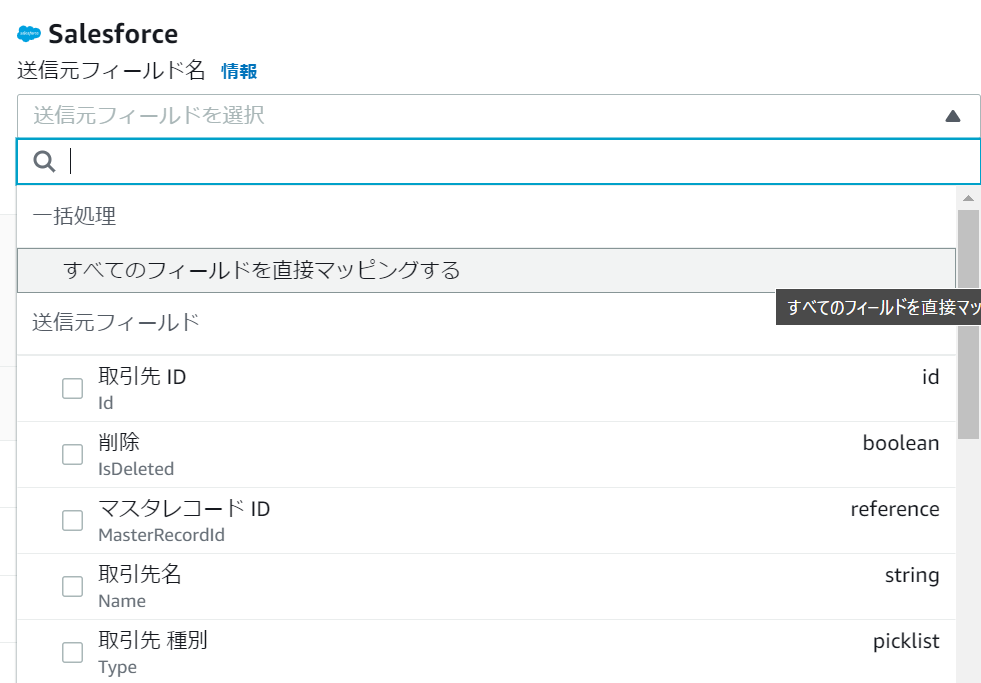
送信元先の組み合わせ次第では式を使用してフィールドのマッピングも行えそうです。

マッピング設定後です。

またマッピング設定ではフィールドオプションを使用することができ、
- 新規追加フィールドの自動インポート(ただし、すべてのフィールドマッピング時のみ)
- 削除されたレコードのインポート
の2つを設定できます。

フィルターと妥当性確認を追加
AppFlowでは妥当性確認オプションを使用でき、例えば不正データが取り込み時にフローを強制終了する、またはレコードを取り込まない、などといった判断をAppFlow側でさせることが可能です。

他にもフィルターに一致したもの、特定の文字列を含んだもの、特定日付よりも最新のもの、等複数の条件で取り込み対象のレコードを絞ることもできるようになっています。

フローをアクティブ化または実行する
最後に確認画面で全部の設定内容を確認して問題なければフローを作成します。
作成できたらこのようにフローの詳細設定が表示されます。
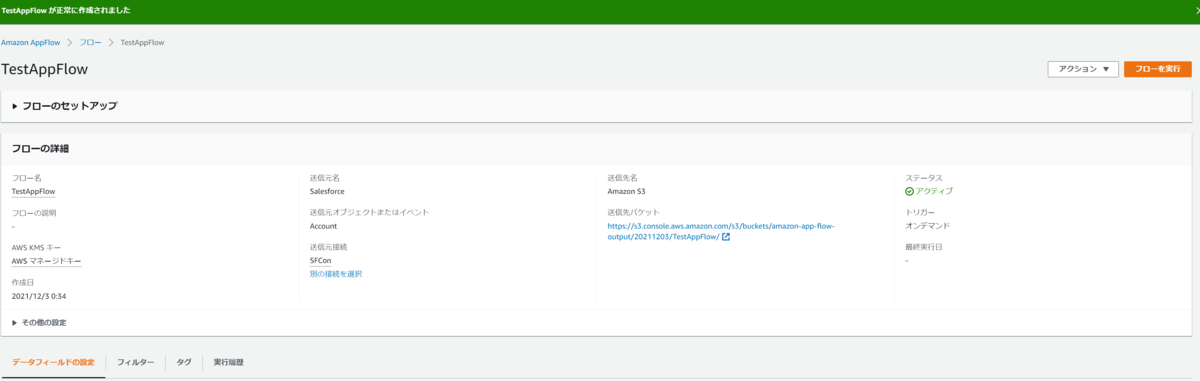
もしフローを修正したい場合は変更可能な項目は限定されており、
の8項目のみになります。
注意点として、送信元の対象データの指定は初回のフロー作成時にしか指定できないので、異なるデータを連携させたいとなった場合は、フロー自体を新規で作成する必要があります。
オンデマンド実行を設定しているのでコンソールからフローを実行してみます。
正常に完了するとコンソール上部にメッセージと処理されたレコード数、転送サイズ、所要時間が表示されます。

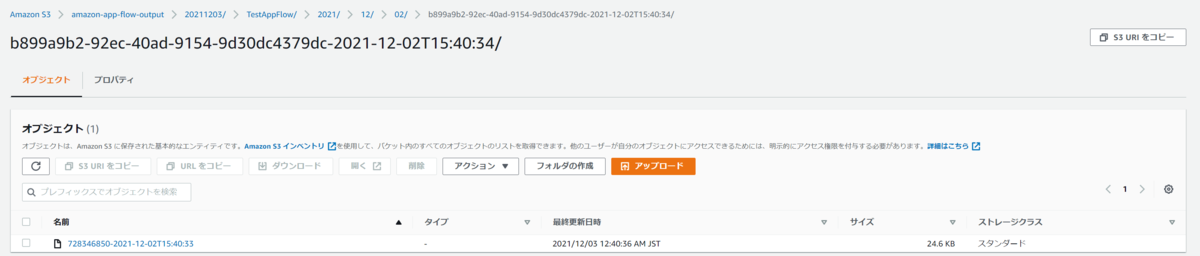
S3に出力されたファイルを確認してみます。
出力先のパスはフロー設定時に確認した、S3バケット/指定したプレフィックス/フロー名/時間/ランダム文字列のフォルダになっています。
ファイル名はランダム文字列とタイムスタンプを足したような名前になっていることが見えてわかります。
わかりづらいですが、これでもparquet形式として出力されています。
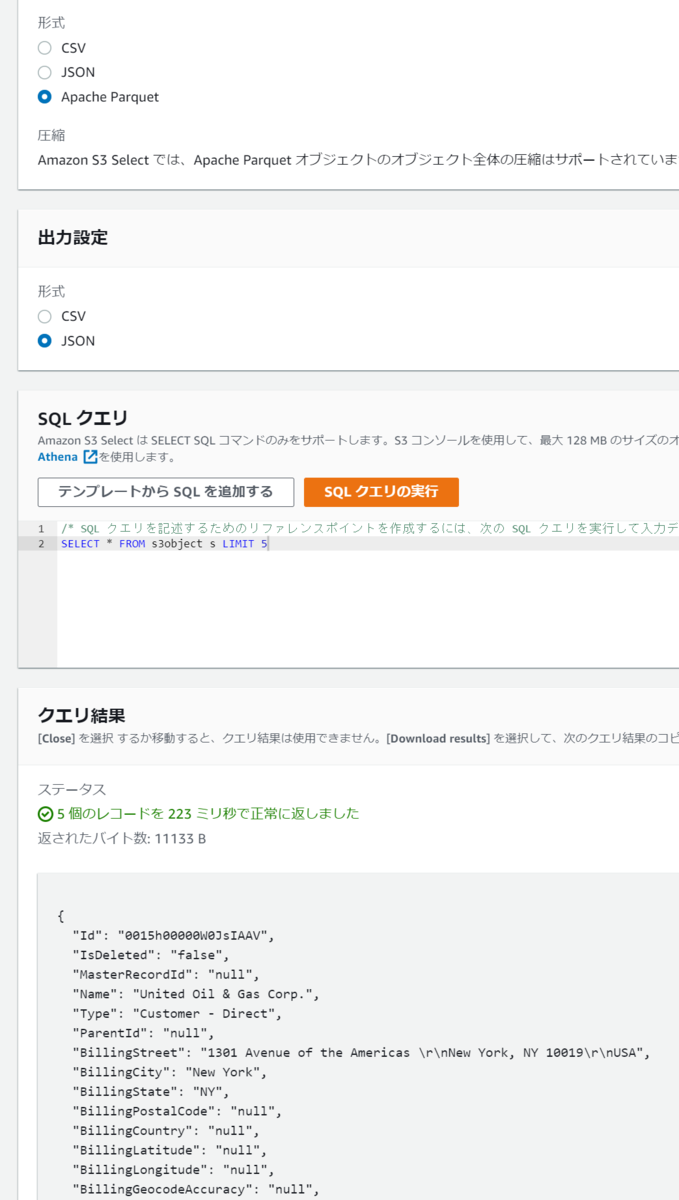
念のためS3 SelectでParquet指定でクエリするとちゃんとファイルの中身がクエリできることを確認できます。
また先ほどは気づいていませんでしたが、S3に出力されるファイルには圧縮形式を指定することができないため、例えばparquet.snappyのような圧縮されたファイルを出力するのは難しいようです。
作成後確認
一連の流れと設定項目は確認したので、最後に管理項目側上でどの項目にリソースが追加されたのか見ていきます。
・コネクタ
特に追加されてません。(当たり前ですが)

・フロー
作成したフローが一覧に表示されています。

・接続
フロー作成時に一緒に作成した接続情報が表示されています。
接続情報は複数作られるのを想定しているのか、上部のコネクタを指定しないと何も表示されないようになっています。


・ユーザー
特に追加されてません。
というかこの項目は必要なんでしょうか。。

感想及び所感
というわけでAmazon AppFlowの設定をフロー作成の流れに沿って確認していきました。
マネージドサービスなので機能に制約はありますが、そこまで複雑なことをさせないということであれば使いやすいサービスなのではと思います。
ただ、2021/11/18にあったアップデートでGlue DataBrewがAppFlowとのコンソール統合が発表されたので、Glue DataBrewと併用することでデータ変換などの処理はAppFlow標準より詳細にできるため、要件次第ではこちらも使ってみるのも良いかもしれません。
aws.amazon.com