SaaSアプリケーションからAWSにデータを連携するとなったときに、Amazon AppFlowサービスを使えば簡単にデータを連携させることができます。(AWSドキュメントに書いてある限りは)
今回はそのAppFlowを使う機会が出てきそうだったので、お試しがてら使ってみることにします。
尚、SaaSサービスはすぐには準備できないので、S3 to S3で試すことにします。
実施作業
準備
S3 to S3なので、インアウト用のS3バケットを作成しておきます。

サンプルデータは良さげなものが見つからなかったので、とりあえず目についた以下のサイトで作ったものを利用します。
kazina.com
データの中身はこんな感じです。
これは完全ダミーのデータなので、個人情報的にも問題ないようになっています。

ファイルはインプット用のS3に格納しておきます。

フロー作成
それでは早速フローを作っていきます。
マネコンからAppFlowコンソールに移動して、フローを作成を押下します。

フローの設定画面に移動します。

以下の5つの手順で作成するようです。
- 手順1:フローの詳細を指定
- 手順2:フローを設定
- 手順3:データフィールドをマッピング
- 手順4:フィルターを追加する
- 手順5:確認して作成
手順1:フローの詳細を指定
フローの名前を説明を適当に入力して、次へを押下します。

手順2:フローを設定
次にフローを設定していきます。
送信元の設定では、先ほどファイルをアップロードしたS3バケットを指定します。
データ形式はCSVかJsonlのみが対応しているみたいです。
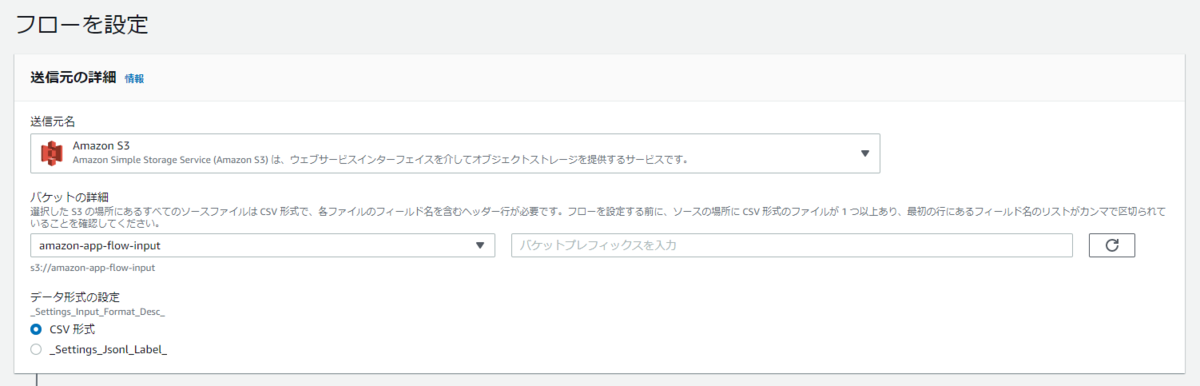
続いて送信先ですが、こちらも事前に作成したS3バケットを指定します。

その他の設定を展開するともう少し詳細に設定することができます。
今回は何も変更せずに次に向かいます。

送信元、送信先が設定できたらフローのトリガーを設定します。
トリガーは
- オンデマンド実行
- スケジュール実行
- イベント実行
の3種類から選べます。
今回はオンデマンド実行にしておきましょう。

ここまで入力して次へを押下したら送信元の設定でエラーが出てました。

ファイルの格納先を変更したらエラーが出なくなったので、次にいきます。

手順3:データフィールドをマッピング
データの設定ができたら今度はデータフィールドをマッピングします。
マッピングされたフィールドを含む.csvファイルは今回準備していないので、手動でマッピングします。

マッピング設定で送信元のフィールドと送信先のフィールドをマッピングできるのですが、ここで予想外の事象が発生しました。
なんとサンプルデータのカラム列が日本語で作成されているので、文字化けが発生していました。。
一応一括処理という選択肢があるみたいなので、とりあえず設定してみます。

(まぁそうですよねぇという気持ち)

オプションとして妥当性確認をすることも可能です。

条件には
- 値が負の場合
- 値がnullかない場合
- 値が0の場合
- 値にテキストが含まれる場合
のよくありそうなケース4種類が設定可能で、致命的な問題なら「フローを終了」、単純に異常値なら「レコードを無視」という判定をさせることができます。(今回は使いません)


手順4:フィルターを追加する
フィルターはサポートされていない設定なのでそのまま次へを押下します。

手順5:確認して作成
最後に設定を確認してフローを作成します。

フローの実行
フローが作成できたので実行してみます。

上手くいったようです。

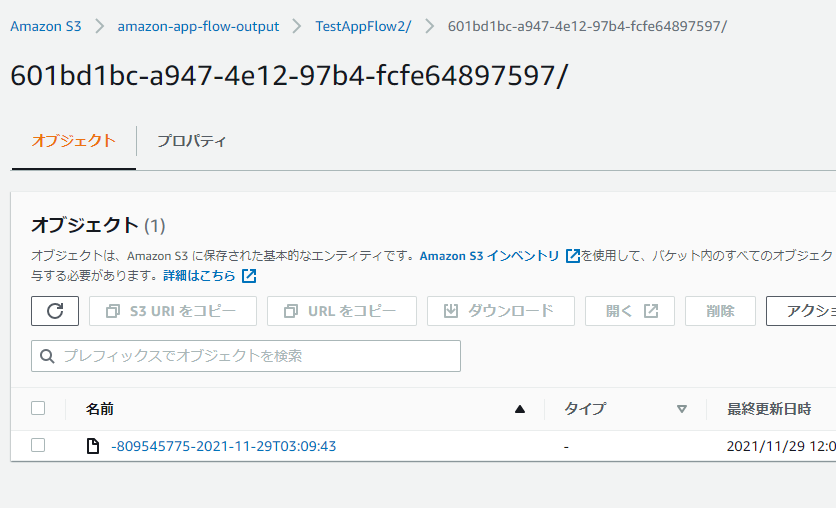
出力はされていたのですが、明らかにファイル名がおかしいものになっていました。

S3 Selectでは一応JSON形式で見れました。
ただ明らかに日本語に対応してなさそうな感じです。




感想及び所感
AppFlowの構築の流れはわかりましたが、日本語データが文字化けする問題は他のデータソースからの送信でも発生するのかが気になりました。
時間があればその辺りも試してい見たいと思います。